
Latest
Jun
07

Are Your Iceberg Writes Optimized?
How do Iceberg Distribution Modes, Advisory Partition Size, AQE, and Target File Sizes work together? How to mitigate slow writes and control file sizes during writes?
18 min read
Jan
13
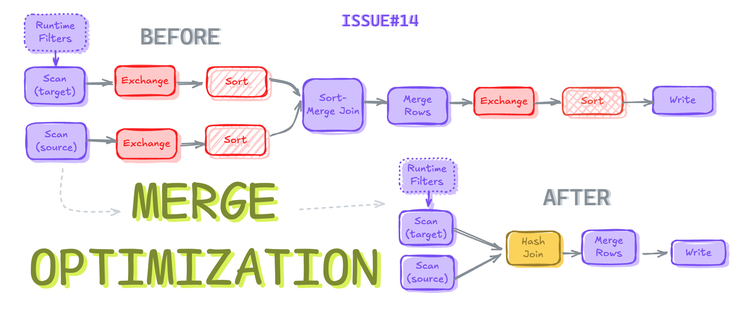
Optimizing Iceberg MERGE Statements
How can you eliminate shuffling, sorting, and push-down filters to optimize the Apache Iceberg merge statements?
11 min read
Dec
25
Building A Lightweight Spark Exception Logger
How to Create a Spark Exception Logger and Test It Locally Using DuckDB, MinIO, and a Standalone Spark Cluster
9 min read
Dec
15

Selecting between Double and Decimal Data Type To Avoid Unexpected Results
How to choose between Double and Decimal data types for your tables/datasets, why does it matter, and when to choose which one?
4 min read
Dec
08
How withColumn Can Degrade the Performance of a Spark Job?
Reasons and Solutions to Avoid Performance Degradation due to excessive use of `.withColumn()` in Apache Spark
8 min read
Nov
28

Shuffle-less Join, a.k.a Storage Partition Join in Apache Spark - Why, How and Where?
A Deep Dive into Shuffle-less joins (Storage Partitioned Joins) in Apache Spark to improve Join performance when using V2 Data Sources.
10 min read
Oct
12

Enhancing Spark Job Performance with Multithreading
It covers a Spark Job Optimization technique to enhance the performance of independent running queries using Multithreading in Pyspark.
7 min read
Feb
13

EMRFS S3 Optimized Committer and Committer Protocol for Improving Spark Write Performance - Why and How?
What are EMRFS S3 Optimized Committer and EMRFS S3 Optimized Committer Protocol and how to use and identify if these are working for your Spark Jobs to improve write performance?
30 min read
Jan
24

Copy-on-Write or Merge-on-Read? What, When, and How?
Copy-on-Write or Merge-on-Read? Optimizing Row-level updates in Apache Iceberg Table by understanding both the approaches and deciding when to use which approach and its impact on the Read and Write speed of the table.
How to identify these using Iceberg Metadata tables on AWS?
15 min read
Jan
17

Apache Iceberg - Architecture Demystified
A detailed explanation of Apache Iceberg Architecture and how it evolves when data is inserted into the table.
11 min read