Apache Iceberg - Architecture Demystified

This blog post details what happens under the hood when interacting with Apache Iceberg Tables. It explains how the different components in Apache Iceberg Architecture work with a simple example in Apache Spark with Python.
What is Apache Iceberg?
Apache Iceberg is an Open Table Format, OTF created in 2017 at Netflix by Ryan Blue and Daniel Weeks. This project was open-sourced and donated to Apache Software Foundation in 2018.
OTFs are also known as Modern Data Lake Table Formats that approach the defining table as a canonical list of files, providing metadata for engine information on which files make up the table, not which directories, unlike the Hive table format. This granular approach to defining a table provides features like ACID Transactions, consistent reads, safe writes by multiple readers and writers at the same time, Time Travel, easy schema evolution without rewriting the entire table, and more.
All these features come with performance benefits as its architecture provides metadata which helps in avoiding excessive file listing that helps in quicker query planning.
Alrighty, now to the main discussion of this blog.
Apache Iceberg Architecture
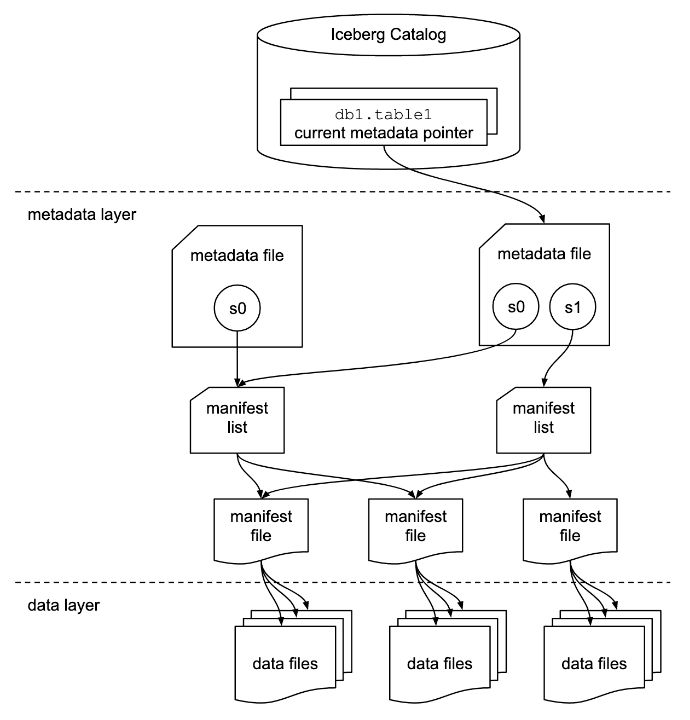
Apache Iceberg table has three different layers - Catalog Layer, Metadata Layer, and Data Layer.
Let's take a peek inside these different layers.
Data Layer
This is the layer where the actual data for the table is stored and is primarily made of data files. Apache Iceberg is file-format agnostic and it currently supports Apache Parquet, Apache ORC, and Apache Avro. It stores the data by default in Apache Parquet file format.
This file-format agnostic provides the ability for a user to choose the underlying file format based on the use case, for example, Parquet might be used for a large-scale OLAP analytics table, whereas Avro might be used for a low-latency streaming analytics table.
The data layer is backed by a distributed file system like HDFS or a cloud object storage like AWS S3. This enables building data lakehouse architectures that can benefit from these extremely scalable and low-cost storage systems
Metadata Layer
This layer contains all of the metadata files for an Iceberg table. It has a tree structure that tracks the data files and metadata about them along with the details of the operation that made them.
The files in this layer are immutable files so everytime an insert, merge, upsert or delete operation happens on the table, a new set of files are written.
This layer contains three file types:
Manifest Files
Manifest files keep track of files in the data layer along with the additional details and statistics about each file. It stores all this information in avro file format.
Manifest Lists
Manifest lists keep track of manifest files, including the location, the partitions it belong to, and the upper and lower bound for partition columns for the data it tracks. It stores all this information in avro file format.
A Manifest list file is a snapshot of an Iceberg Table as it contains the details of the snapshot along with snapshot_id that has added it.Metadata Files
Metadata files keep track of Manifest Lists. These files include the information about the metadata of the Iceberg Table at a certain point in time i.e. table's schema, partition information, snapshots, and which snapshot is the current one.
All this information is stored in a json format file.
Catalog Layer
Within the Catalog layer, there is a reference or pointer, that points to the current metadata file for that table.
As catalog is an interface and the only requirement for an Iceberg catalog is that it needs to store the current metadata pointer and provide atomic guarantees, there are different backends that can serve as the Iceberg catalog like Hadoop, AWS S3, Hive, AWS Glue Catalog and more. These different implementations store the current metadata pointer differently.
Alrighty, that's enough of the theoretical part, let's dive deeper into what all these files are, and when these are created under the hood with an easy-to-follow example with Apache Spark.
Diving Deeper with an example
In this example, we will be creating a simple Iceberg table and inserting some records into it to understand how different architectural components are created and what all these components store.
In addition to this, we will also be looking into the Iceberg table metadata tables that can be queried to get different metadata-related information instead of reading the metadata JSON or avro files.
Defining Catalog
Let's start with configuring an Iceberg catalog and understand how can we use different catalog implementations.
Understanding different Spark Configuration for Iceberg Catalog
- The name of an Iceberg catalog can be defined using
spark.sql.catalog.<catalog-name>with valueorg.apache.iceberg.spark.SparkCatalogororg.apache.iceberg.spark.SparkSessionCatalog - Once the Iceberg catalog is defined, the
typefor catalog needs to be defined, thistypedefines which catalog implementationcatalog-impland IO implementationio-implfor reading/writing a file will be used. Some of the types supported by Iceberg arehadoopandhive. - For using a custom implementation of the Iceberg catalog e.g. using
AWS Glue Catalogas Iceberg catalog,catalog-implclass needs to be mentioned. It can be mentioned usingspark.sql.catalog.<catalog-name>.catalog-implasorg.apache.iceberg.aws.glue.GlueCatalog. - It's mandatory to define either a
typeorcatalog-implfor a defined catalog as this defines how the current metadata pointer will be stored. warehouseis a required catalog property to determine the root path of the catalog in storage. By default, all the Iceberg tables location created within this defined catalog refer to this as the root path.warehouseis configured usingspark.sql.catalog.<catalog-name>.warehouse- Depending on which catalog implementation is being used,
warehouselocation can also be changed during runtime. More details on this can be seen here. - This is just scratching the surface of the Iceberg Catalog.
Keeping simplicity for the sake of explanation in mind, I will be creating a catalog named local that is of type hadoop
from pyspark.sql import SparkSession
# Avro jar to look into Manifest list and manifest file data.
spark = SparkSession.builder \
.master("local[4]") \
.appName("iceberg-poc") \
.config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.2,org.apache.spark:spark-avro_2.12:3.5.0')\
.config('spark.sql.catalog.local','org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.local.type','hadoop') \
.config('spark.sql.catalog.local.warehouse','./warehouse') \
.getOrCreate()Initiating Spark Session with local catalog of type hadoop
Creating an Iceberg Table
Let's create an Iceberg table called sales.
# Creating an Iceberg table
spark.sql("""CREATE TABLE local.db.sales (
order_number bigint,
product_code string,
year_id int,
month_id int)
USING iceberg
PARTITIONED BY (
year_id,
month_id)""")Creating sales table in local catalog
On successful creation of table, as we are using catalog of type hadoop it creates:
-
version-hint.txtfile: This file is used by the engines to identify the latest metadata file version. - Metadata file called
v1.metadata.json: As the table is created, this file stores the table schema details like fields in the schema, partition columns, current-schema-id, properties, and more.
{
"format-version" : 2,
"table-uuid" : "c11d9694-b83f-41a7-871f-e4f6c0174008",
"location" : "/usr/documents/warehouse/db/sales",
"last-sequence-number" : 0,
"last-updated-ms" : 1705148131603,
"last-column-id" : 4,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "order_number",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "product_code",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "year_id",
"required" : false,
"type" : "int"
}, {
"id" : 4,
"name" : "month_id",
"required" : false,
"type" : "int"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "year_id",
"transform" : "identity",
"source-id" : 3,
"field-id" : 1000
}, {
"name" : "month_id",
"transform" : "identity",
"source-id" : 4,
"field-id" : 1001
} ]
} ],
"last-partition-id" : 1001,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "akashdeepgupta",
"write.parquet.compression-codec" : "zstd"
},
"current-snapshot-id" : -1,
"refs" : { },
"snapshots" : [ ],
"statistics" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
}Content of v1.metadata.json file
As this table has no data written into it as of now, thecurrent-snapshot-idis mentioned as-1. Also as there are no data files so, there won't be any manifest lists and manifest files created for the table.
All the metadata-related details can be seen in metadata_log_entries metadata tables:
# querying metadata log entries table
spark.sql("select * from local.db.sales.metadata_log_entries").show(truncate=False)Querying metadata_log_entries table
+-----------------------+-----------------------------------------------------------+------------------+----------------+----------------------+
|timestamp |file |latest_snapshot_id|latest_schema_id|latest_sequence_number|
+-----------------------+-----------------------------------------------------------+------------------+----------------+----------------------+
|2024-01-13 17:45:31.603|/usr/documents/warehouse/db/sales/metadata/v1.metadata.json|NULL |NULL |NULL |
+-----------------------+-----------------------------------------------------------+------------------+----------------+----------------------+Output from metadata_log_entries table
As there is no data present in the table, all the other details in this table is NULL
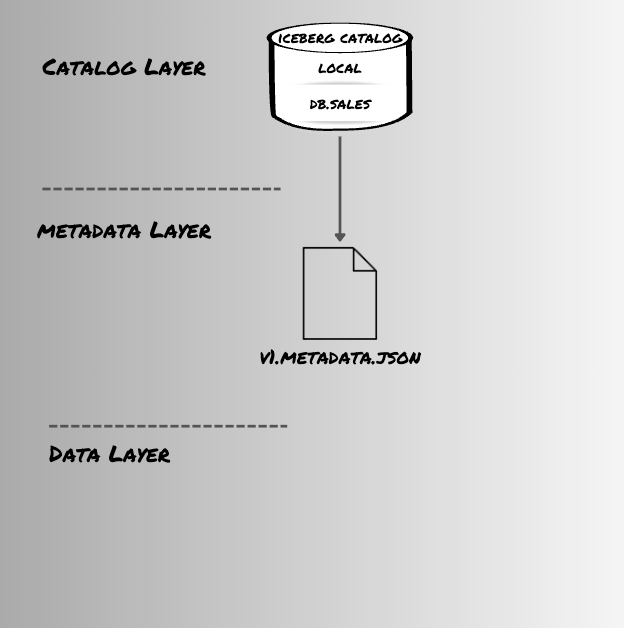
db.sales table creation in local Iceberg catalogLoading data in sales Iceberg Table
Let's load some data into the sales table and see how the table metadata tree evolves on the addition of data files in the table.
from pyspark.sql import Row
data_row = [Row(order_number=10107, product_code='S10_1678', year_id=2023, month_id=12),
Row(order_number=10121, product_code='S10_1678', year_id=2023, month_id=12)]
df = spark.createDataFrame(data_row)
df.show()Creating a dataframe with data to be loaded in sales table
+------------+------------+-------+--------+
|order_number|product_code|year_id|month_id|
+------------+------------+-------+--------+
| 10107| S10_1678| 2023| 12|
| 10121| S10_1678| 2023| 12|
+------------+------------+-------+--------+Data in dataframe
# Loading data into sales table
iceberg_tbl = 'local.db.sales'
df.writeTo(iceberg_tbl).append()Appending data into sales table
While writing data into the table, the query engine (in this case, Spark):
- Gets the location of the current metadata file by looking into the catalog
version-hints.txtfile (as the catalog type ishadoop). In this case, the content ofversion-hints.txtis1. - This gives the current metadata file version and the engine reads the
warehouse/local/db/sales/metadata/v1.metadata.jsonfile. This lets Spark understand the table schema and the partitioning strategy of the table. - Spark first writes the records as Parquet data files based on the partitioning in this case based on
year_idandmonth_id - After data files are written, it writes the
manifest filewith data file details and statistics provided to it. - Next, the engine creates a
manifest listto keep track of themanifest file. This file includes information such as the manifest file’s path, the number of data files/rows added or deleted, and statistics about partitions. - Finally, a new metadata file is created,
v2.metadata.jsonwith a new snapshot andversion-hints.txtis updated with2.
Let's look at how the architecture for this table evolved using Iceberg metadata tables.
Metadata Tables
Apache Iceberg metadata tables can be used to better understand your Iceberg tables and how it's evolved over time.
metadata_log_entries
Keeps track of the evolution of the table by logging the metadata files generated during table updates.
# Reading from metadata_log_entries table
spark.sql(f"select * from {iceberg_tbl}.metadata_log_entries").show(truncate=False)Checking metadata_files added after inserting data in the table.
+-----------------------+-----------------------------------------------------------+-------------------+----------------+----------------------+
|timestamp |file |latest_snapshot_id |latest_schema_id|latest_sequence_number|
+-----------------------+-----------------------------------------------------------+-------------------+----------------+----------------------+
|2024-01-13 17:45:31.603|/usr/documents/warehouse/db/sales/metadata/v1.metadata.json|NULL |NULL |NULL |
|2024-01-13 18:41:21.148|/usr/documents/warehouse/db/sales/metadata/v2.metadata.json|7931974344861414873|0 |1 |
+-----------------------+-----------------------------------------------------------+-------------------+----------------+----------------------+Output from metadata_log_entries after data is written
snapshots
Maintains metadata about every snapshot for a given table, each representing a consistent view of the dataset at specific time.
This mainly keeps details of manifest list files as these defines the snapshots for an Iceberg Table.
# Reading from snapshots table
spark.sql(f"select * from {iceberg_tbl}.snapshots").show(truncate=False)Checking manifest_file and snapshot details
+-----------------------+-------------------+---------+---------+---------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|committed_at |snapshot_id |parent_id|operation|manifest_list |summary |
+-----------------------+-------------------+---------+---------+---------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|2024-01-13 18:41:21.148|7931974344861414873|NULL |append |/usr/documents/warehouse/db/sales/metadata/snap-7931974344861414873-1-ba683ade-8c44-45ee-92e4-d5c69bdcd9ad.avro|{spark.app.id -> local-1705147879887, added-data-files -> 1, added-records -> 2, added-files-size -> 1346, changed-partition-count -> 1, total-records -> 2, total-files-size -> 1346, total-data-files -> 1, total-delete-files -> 0, total-position-deletes -> 0, total-equality-deletes -> 0}|
+-----------------------+-------------------+---------+---------+---------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+Output from snapshots table after data is written.
manifests
The manifests table details each of the table’s current file manifests.
# Reading from manifests table
spark.sql(f"select * from {iceberg_tbl}.manifests").show(truncate=False)Checking manifest files from manifest table
+-------+---------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+----------------------------------------------------+
|content|path |length|partition_spec_id|added_snapshot_id |added_data_files_count|existing_data_files_count|deleted_data_files_count|added_delete_files_count|existing_delete_files_count|deleted_delete_files_count|partition_summaries |
+-------+---------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+----------------------------------------------------+
|0 |/usr/documents/warehouse/db/sales/metadata/ba683ade-8c44-45ee-92e4-d5c69bdcd9ad-m0.avro|7308 |0 |7931974344861414873|1 |0 |0 |0 |0 |0 |[{false, false, 2023, 2023}, {false, false, 12, 12}]|
+-------+---------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+----------------------------------------------------+Output from manifests table after data is written
files
shows the details of current data files in the table. It keeps detailed information about each data file in the table, from its location and format to its content and partitioning specifics.
# Reading from files table
spark.sql(f"select * from {iceberg_tbl}.files").show(truncate=False)Checking details about data files created while writing the data
+-------+---------------------------------------------------------------------------------------------------------------------------+-----------+-------+----------+------------+------------------+------------------------------------+--------------------------------+--------------------------------+----------------+--------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------+------------+-------------+------------+-------------+------------------------------------------------------------------------------------------------------------------------------+
|content|file_path |file_format|spec_id|partition |record_count|file_size_in_bytes|column_sizes |value_counts |null_value_counts |nan_value_counts|lower_bounds |upper_bounds |key_metadata|split_offsets|equality_ids|sort_order_id|readable_metrics |
+-------+---------------------------------------------------------------------------------------------------------------------------+-----------+-------+----------+------------+------------------+------------------------------------+--------------------------------+--------------------------------+----------------+--------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------+------------+-------------+------------+-------------+------------------------------------------------------------------------------------------------------------------------------+
|0 |/usr/documents/warehouse/db/sales/data/year_id=2023/month_id=12/00000-12-5d678192-f2f9-4770-a5ad-203d7e244838-00001.parquet|PARQUET |0 |{2023, 12}|2 |1346 |{1 -> 54, 2 -> 80, 3 -> 72, 4 -> 72}|{1 -> 2, 2 -> 2, 3 -> 2, 4 -> 2}|{1 -> 0, 2 -> 0, 3 -> 0, 4 -> 0}|{} |{1 -> [7B 27 00 00 00 00 00 00], 2 -> [53 31 30 5F 31 36 37 38], 3 -> [E7 07 00 00], 4 -> [0C 00 00 00]}|{1 -> [89 27 00 00 00 00 00 00], 2 -> [53 31 30 5F 31 36 37 38], 3 -> [E7 07 00 00], 4 -> [0C 00 00 00]}|NULL |[4] |NULL |0 |{{72, 2, 0, NULL, 12, 12}, {54, 2, 0, NULL, 10107, 10121}, {80, 2, 0, NULL, S10_1678, S10_1678}, {72, 2, 0, NULL, 2023, 2023}}|
+-------+---------------------------------------------------------------------------------------------------------------------------+-----------+-------+----------+------------+------------------+------------------------------------+--------------------------------+--------------------------------+----------------+--------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------+------------+-------------+------------+-------------+------------------------------------------------------------------------------------------------------------------------------+Output from files table after data is written
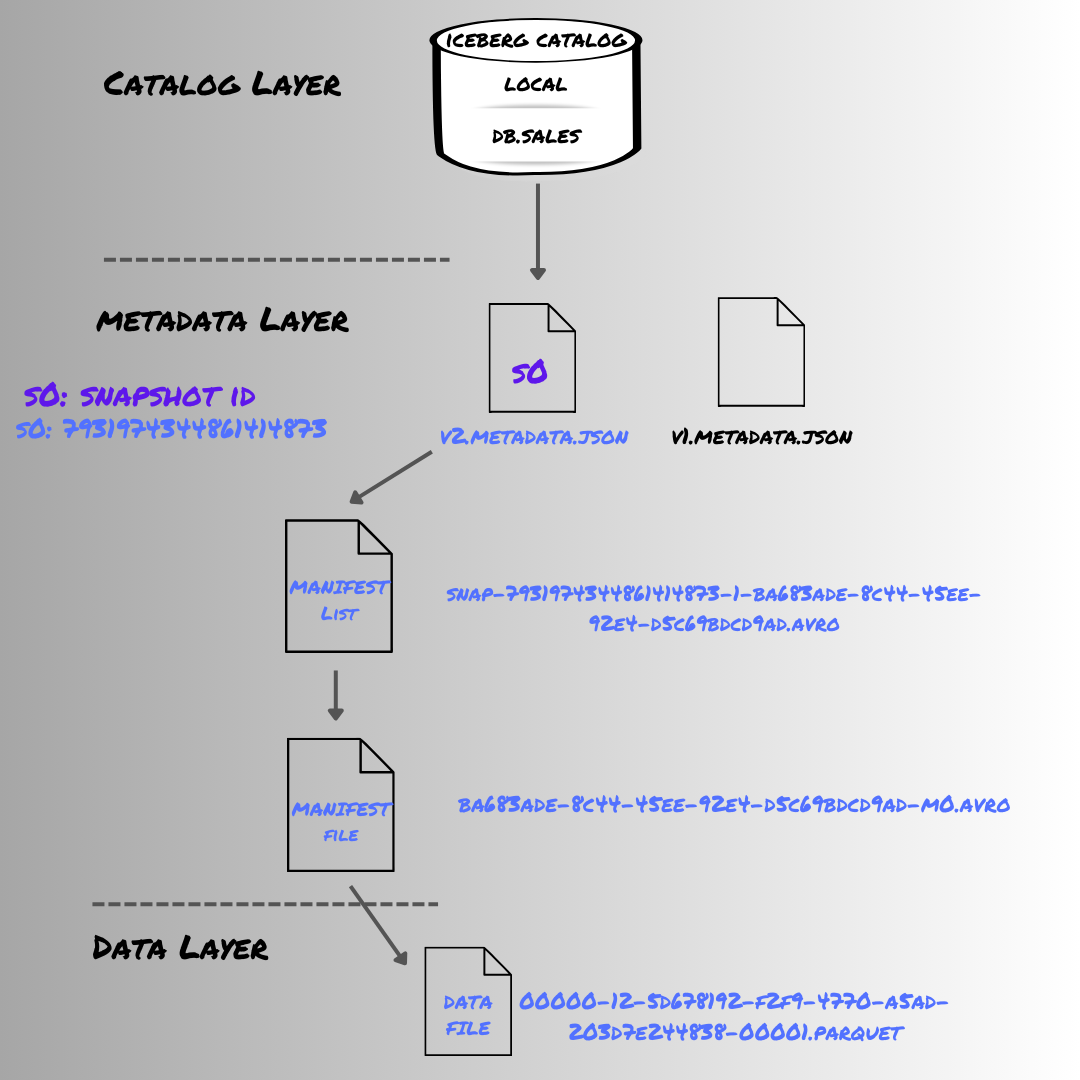
db.sales is populated with data in local Iceberg catalogThat's it for this one folks!!
If you want to continue to dive deeper, you can checkout this next:

If it has added any value to you and want to read more content like this, subscribe to the newsletter, it's free of cost and I will make sure every post is worth your time.





Member discussion