Building Discord Bot with AWS Serverless - Part 3

This blog post is part of the Let's Build Series, where we pick and build an idea.
In the inaugural blog post of this series, we developed VerifyRequest Lambda, discussed the code design decisions made, deployed it along with API Gateway on AWS, and finally integrated it with Discord bot using interactions endpoint URL.
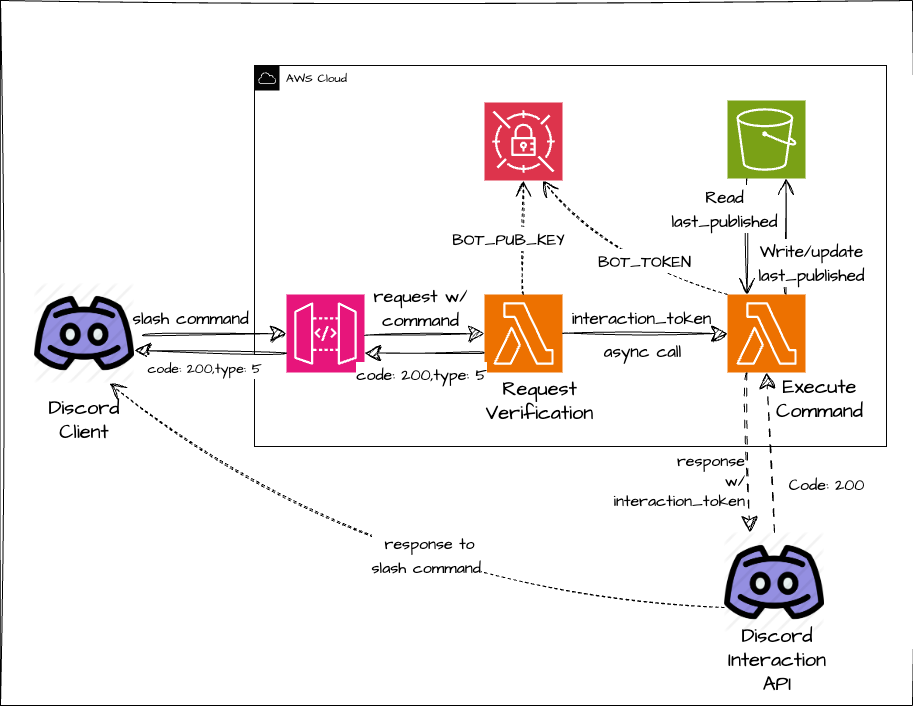
In this final part of this blog series, we will implement a Lambda function to execute a command that will fetch the last published AWS blog posts and send a response to Discord Interaction API to post it into the Discord server as an embed.
Asynchronously calling Lambda
VerifyRequest Lambda implemented in Part 2 on successful request validation and for command type 4, triggers the ExecuteCommand Lambda asynchronously.
import boto3
import os
async def trigger_lambda(event):
command_lambda_arn = os.environ.get("COMMAND_LAMBDA_ARN")
# Trigger the Lambda function asynchronously
response = lambda_client.invoke(
FunctionName=command_lambda_arn,
InvocationType="Event",
Payload=json.dumps(event),
)
# Return the response
return responseThe important thing to know here is that when a command is submitted to a bot, it creates an interaction token corresponding to that interaction which is passed as in the request sent to AWS API Gateway.
This entire request with token is passed to the asynchronous call to Execute Command Lambda.
Command Execution Lambda
This is where the fun part begins as you don't have to worry about request verification anymore and you can implement the logic for your command to work.
Let's see how sending a response to Discord Interaction API works and what is required to send the response to this endpoint:
- Interaction Token, which we are receiving in the event object's body as
tokenthe - Response payload, having
contentorembedat least wrapped into a JSON-like{"content": "command output here."}or{"embeds": [json_embed1, json_embed2]} - Headers:
{"Authorization": f"Bot {BOT_TOKEN}", "Content-Type": "application/json"}BOT_TOKEN: present in Secrets Manager.
- API Endpoint :
https://discord.com/api/v10/webhooks/{application_id}/{interaction_token
Sending response to Discord Interaction API
Let's implement first a simple command /hello that returns Hello World! as a response to make sure our bot is working as expected before implementing any complex logic.
def lambda_handler(event, context):
# Read from Secrets Manager
BOT_TOKEN = sm_response["BOT_TOKEN"]
event_body = json.loads(event["body"])
application_id = event_body["application_id"]
interaction_token = event_body["token"]
command_data = event_body["data"]
command_name = command_data["name"]
FOLLOW_MSG_URL = (
f"https://discord.com/api/v10/webhooks/{application_id}/{interaction_token}"
)
headers = {"Authorization": f"Bot {BOT_TOKEN}", "Content-Type": "application/json"}
if command_name == "hello":
payload = {"content": "Hello World!"}
response = requests.post(
FOLLOW_MSG_URL, headers=headers, data=json.dumps(payload)
)
if response.status_code != 200:
print(f"Error: {response.text}")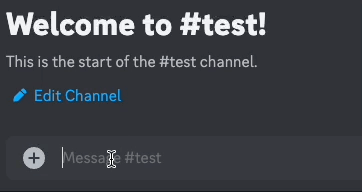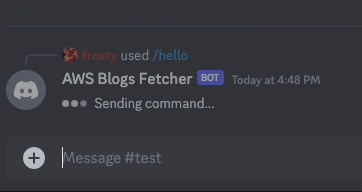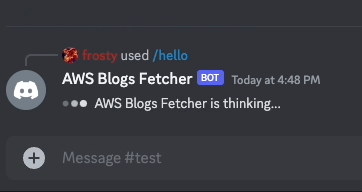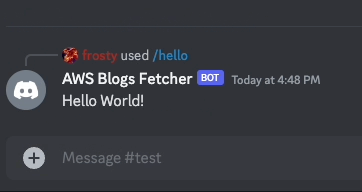
Fetching blogs from AWS RSS Feed and posting them as embeds
We won't be discussing the logic in detail here as it's a pretty straightforward thing to do via feedparser Python package. The entire implementation is well documented in code and can be seen here
The important thing that I want to mention here is the embed limitation.
the combined sum of characters in alltitle,description,field.name,field.value,footer.text, andauthor.namefields across all embeds attached to a message must not exceed 6000 characters
This is handled via a recursive function called manage_embed_length
Fetching only the last published blogs
This is where the S3 read/write via ExecuteLambda comes into the picture. Every time a /fetch BLOG_NAME command is used, it checks for {BLOG_NAME}_LAST_PUBLISHED_DATE.txt and filters the fetched RSS feed based on the blogs that are published after this date.
def get_last_published_date(bucket, key):
try:
response = s3_client.get_object(Bucket=bucket, Key=key)
last_published_date = response["Body"].read().decode("utf-8")
return last_published_date
except Exception as e:
print(e)
return Nonedef lambda_handler(event, context):
.......
aws_blog_name = command_data["options"][0]["value"]
blog_url = os.environ.get(f"{aws_blog_name.upper()}_URL")
s3_bucket = os.environ.get("LAST_UPDATED_S3_BUCKET")
# create s3_key
s3_key = f"aws_rss_bot/last_updates/{aws_blog_name.upper()}_LAST_PUBLISHED_DATE.txt"
# get the last published date from s3 -- can be async
last_published = get_last_published_date(s3_bucket, s3_key)
if last_published:
new_blogs = list(
filter(
lambda blog: datetime.strptime(
blog.published, "%a, %d %b %Y %H:%M:%S %z"
)
> datetime.strptime(last_published, "%d-%m-%Y %H:%M:%S %z"),
blog_posts,
)
)
else:
new_blogs = blog_posts
........filtering blogs based on last_published_date
Mentioning Blog Names and Feed URLs:
AWS Blog feed URLs can be defined either in a DynamoDB, S3 file or in Lambda Environment Variables. It completely depends on how you wanna read those in your Lambda.
I have chosen to define these as Environment Variables as it's easily manageable via the SAM Template and I won't be deploying this Lambda too often.
Environment:
Variables:
BIG_DATA_URL: https://aws.amazon.com/blogs/big-data/feed/
ARCHITECTURE_URL: https://aws.amazon.com/blogs/architecture/feed/
DEVELOPER_URL: https://aws.amazon.com/blogs/developer/feed/
NEWS_URL: https://aws.amazon.com/blogs/aws/feed/
COMPUTE_URL: https://aws.amazon.com/blogs/compute/feed/
STARTUP_URL: https://aws.amazon.com/blogs/startups/feed/
TRAIN_CERT_URL: https://aws.amazon.com/blogs/training-and-certification/feed/Snippet from SAM Template of ExecuteCommand Lambda Environment Variables
This list can be extended or reduced based on what blog posts you want to fetch and stay up to date with.
Let's look this into Action:
If you have read until here, please leave a comment below, and any feedback is highly appreciated. See you in the next post..!!! 😊





Member discussion