Selecting between Double and Decimal Data Type To Avoid Unexpected Results

Until recently, I knew little about choosing between these 2 data types, which can be crucial for your data. This can cause your pipeline to generate unexpected results, especially when working on any domain where precision is paramount, like a Financial or Banking domain project.
Most Data Engineers usually use Double because it can hold a wide range of numbers, we don't have to consider the number of digits before and after decimals, or because processing is faster than decimals.
But when precision is critical, just these reasons for choosing double isn't enough.
TL;DR Choose Decimal whenever precision and accuracy are essential, such as columns holding values for amount, money, conversion rate, aggregated amounts, etc.; otherwise, go with double.
The Issue
Before we explore the reasons in more depth, let's examine the issue that explains why it's crucial.
Let's create a numeric string and cast it into a Double and Decimal data type.
from pyspark.sql import Row
test_row = [Row(amt='12345678901234567890123.1234')]
# Creating the dataframe and casting it to double and decimal type
df = spark.createDataFrame(test_row)\
.withColumn("amt_double", col("amt").cast("double"))\
.withColumn("amt_decimal", col("amt").cast("decimal(30,2)"))
df.show(truncate=False)Creating a Dataframe with Double and Decimal Type
+----------------------------+---------------------+--------------------------+
|amt |amt_double |amt_decimal |
+----------------------------+---------------------+--------------------------+
|12345678901234567890123.1234|1.2345678901234568E22|12345678901234567890123.12|
+----------------------------+---------------------+--------------------------+Look at the dataframe with values.
Everything seems pretty normal here as the data is as expected, i.e., Double stored the value in exponential form while Decimal stored everything as expected.
As Double stored things in exponential form, the common assumption is that it just shows data in exponential form, but the stored value is the same within the exponential form.
But is it???
Let's cast this Double value into a Decimal and see what is stored under that exponential notation:
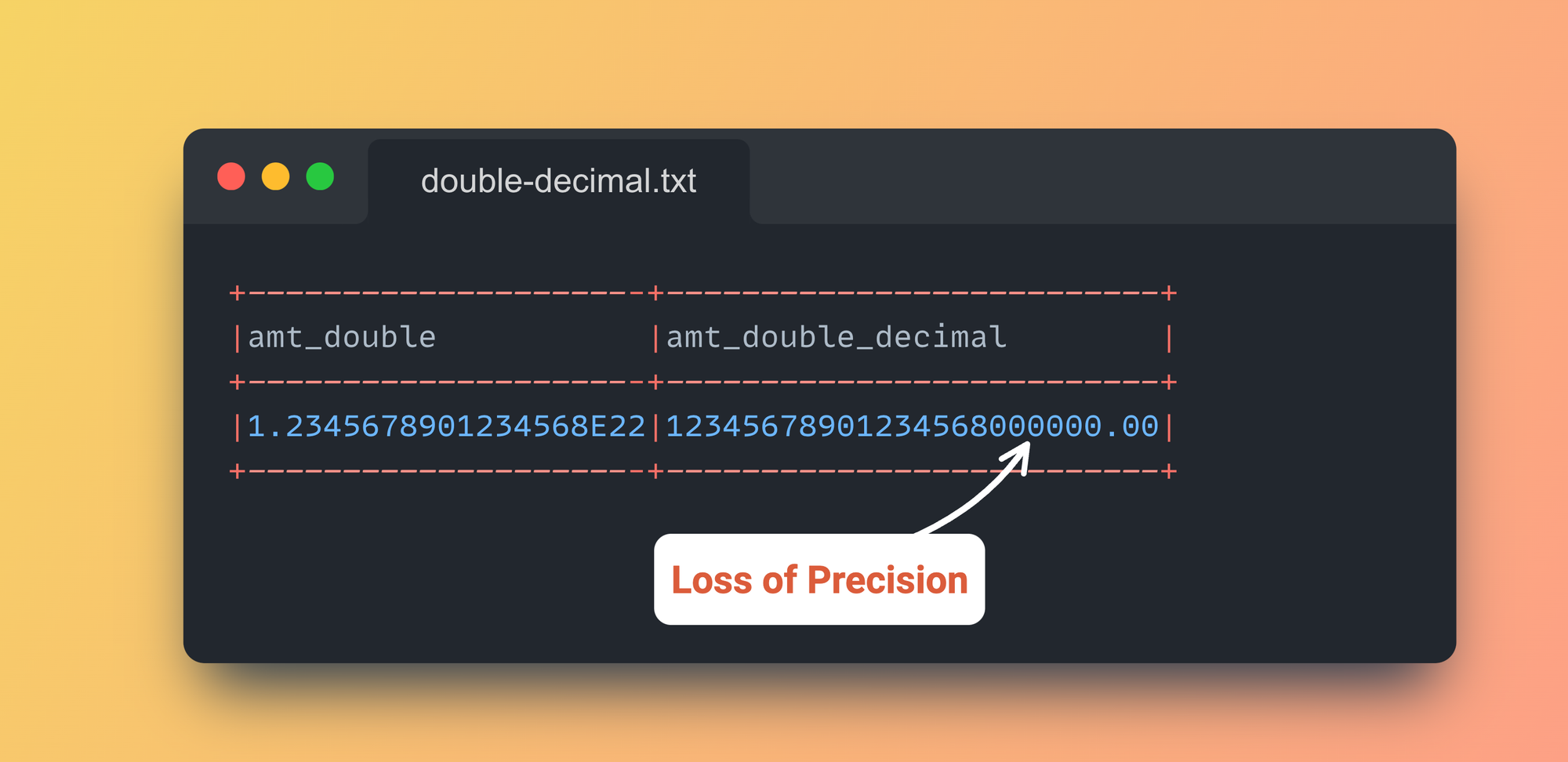
df.select(col("amt_double"), col("amt_double").cast("decimal(30,2)").alias("amt_double_decimal")).show(truncate=False)Conversion of amt from Double to Decimal
+---------------------+--------------------------+
|amt_double |amt_double_decimal |
+---------------------+--------------------------+
|1.2345678901234568E22|12345678901234568000000.00|
+---------------------+--------------------------+Values after conversion of Double to Decimal
See the difference??
Wait!! What the heck? Why are all the values after the 17th digit all 0's?

Yes, that's what is happening under the exponential value of double. This is called "Loss of Precision".
Now, the issue this causes can be obvious, especially when dealing with calculations/aggregations related to amount, money, conversion rates, etc.
We assume everything is calculated and stored as expected. When these results go to some other entity for reporting, everything goes downhill, depending on the impact of these numbers that are being reported.
Reason for the Precision Loss
To understand the reason, we must understand what Range and Precision mean when defining these data types.
Range
The range of a data type specifies the minimum and maximum values it can represent.
Precision
The precision refers to the total number of significant digits a data type can store, regardless of their position relative to the decimal point.
DoubleType
DoubleType in Spark is directly mapped to Java's Double data type and has a range of ±1.7976931348623157E308 and a precision of approximately 15–17 significant decimal digits.
This means that even Double can store around 308 digits, but the accuracy of these digits will be only 15-17 digits. Precision is what defines the number of digits stored accurately.
DecimalType
- DecimalType in Spark uses Java's
BigDecimalfor precision and scale. The precision can go up to 38 digits (user-defined), and the scale (digits to the right of the decimal) must be less than or equal to the precision. By default, it has a precision of 10 and a scale of 0, i.e.,Decimal(10,0)
That's why we lose precision after the 17th digit in Doubles but not in Decimals.
When to choose which one
The simple way to define when to choose which one can directly be decided is based on:
- What kind of data are you storing in the tables or files?
If you are storing data in any column where accuracy is critical, Decimal is the best way to ensure that. This also means that each and every column doesn't have to be of DecimalType. - What is the purpose of the dataset generated as the final result of your process?
If the numbers are to be reported to an external entity where precision matters greatly, Decimal is the best format.
Precision might not matter much if the data you have generated/transformed will be used for ML use cases, and Double is the best option.
This raises a curious question, at least, it did for me:
Why can't we use DecimalType for ML use cases ?
The one reason I know of is that if we store column values as Decimal, Pandas stores them as Object, which might be an issue during EDA (Exploratory Data Analysis), like getting the stats for the columns in the Pandas Dataframe. – Thanks to Sem Sinchenko for pointing this out.
# Converting pyspark dataframe to pandas dataframe
df_pandas = df.toPandas()
# Checking the datatypes of the columns in Pandas dataframe
df_pandas.dtypesViewing how DecimaltType is stored in Pandas dataframe
amt object
amt_double float64
amt_decimal object
dtype: objectamt_decimal is stored as object data type
References
[1] Spark Data Type Documentation
[2] Double Class Doc
That's it for this one! 🚀
You are equipped with everything you need to know to choose between Double and Decimal when modeling your tables or datasets if you have read it until here.
Consider sharing it with your friends and colleagues if you found it valuable or learned something new. ♻️
Got any questions? Put it in the comments.





Member discussion