Copy-on-Write or Merge-on-Read? What, When, and How?

Optimizing reads and writes from Apache Iceberg Tables is a crucial skill that a data engineer needs to know.
To improve Apache Iceberg's read and write performance, one important aspect is how row-level updates are handled. COW (Copy-on-Write) and MOR (Merge-on-Read) are the two approaches that can be configured in an Iceberg table to deal with row-level updates. Knowing how these approaches work internally equips you with the ability to define these in the initial phases of your Iceberg table designs that will keep your tables performant in the long run.
By the end of this blog post, you will be fully equipped with all the knowledge and details that will help you decide, which approach to use for your use case in real-world projects.
This blog post will cover (of course with code samples using PySpark):
- What are COW and MOR? How to configure these?
- What are Delete Files in the data layer and what do they contain?
- When to use which approach?
- How do these help in optimizing reads/writes from the Iceberg Table?
Let's understand the approaches now before we dive into code.
Copy-on-Write
In this approach, if even a single row in a data file is updated or deleted, the associated data file is rewritten with the updated or deleted records.
The new snapshot of the table created because of these operations will point to this newer version of the data file. This is the default approach.
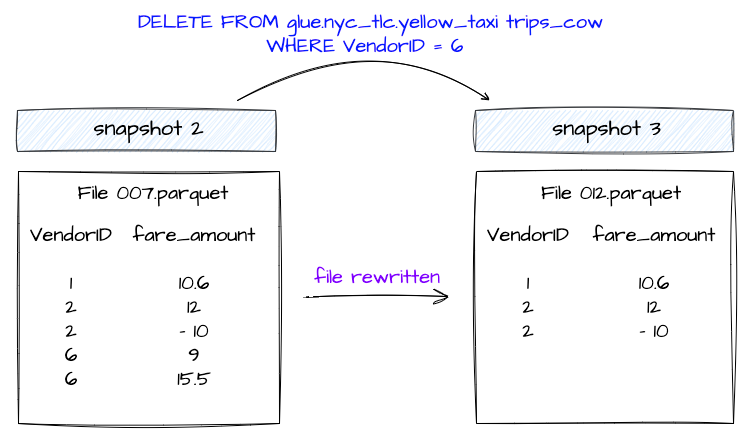
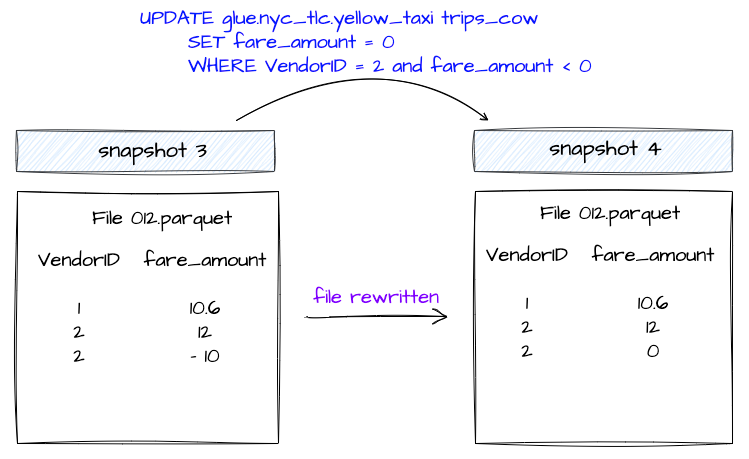
Before we dive into MOR, it's important to understand the Delete Files and what information these files have.
Delete Files
Delete files track which records in the dataset have been logically deleted and need to be ignored when a query engine tries to read the data from an Iceberg Table.
Delete files are created within each partition depending on the data file from where the record is logically deleted or updated.
There are 2 types of delete files based on how these delete files store delete records information.
Positional Delete Files
Positional Delete files store the exact position of the deleted records in the dataset. It keeps track of the file path of the data file along with the position of the deleted records in that file.
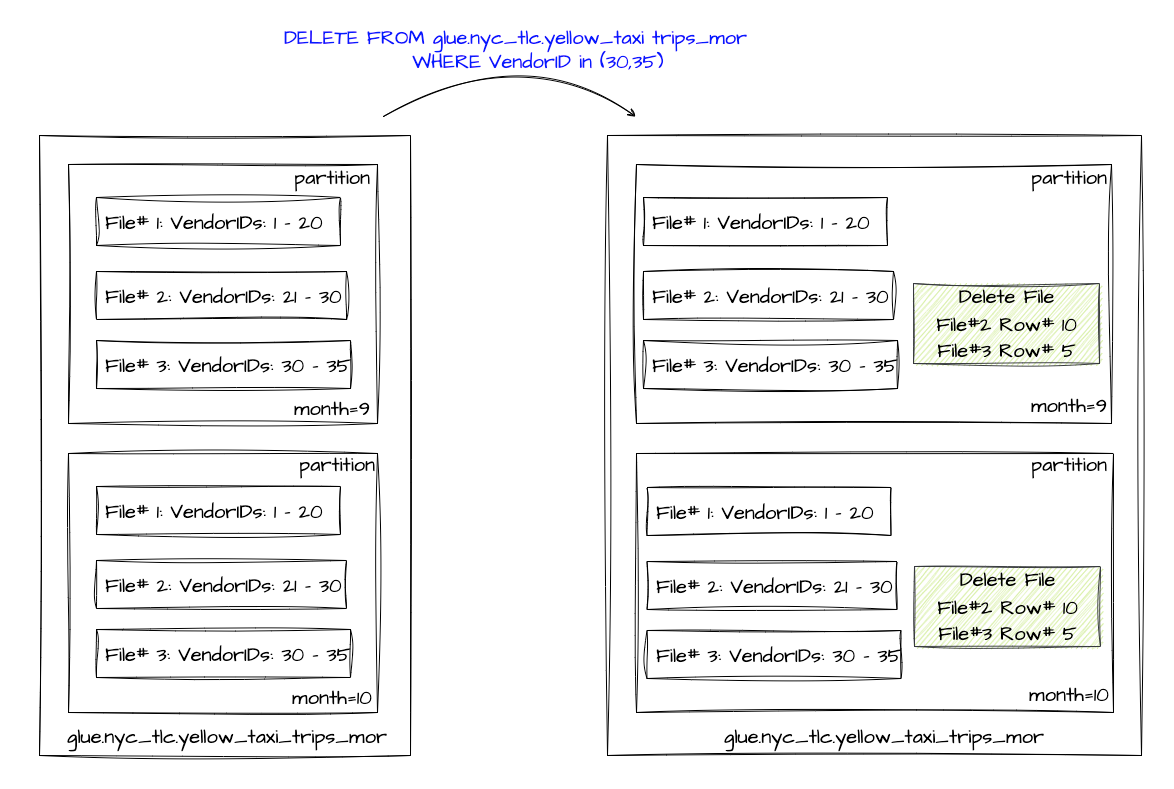
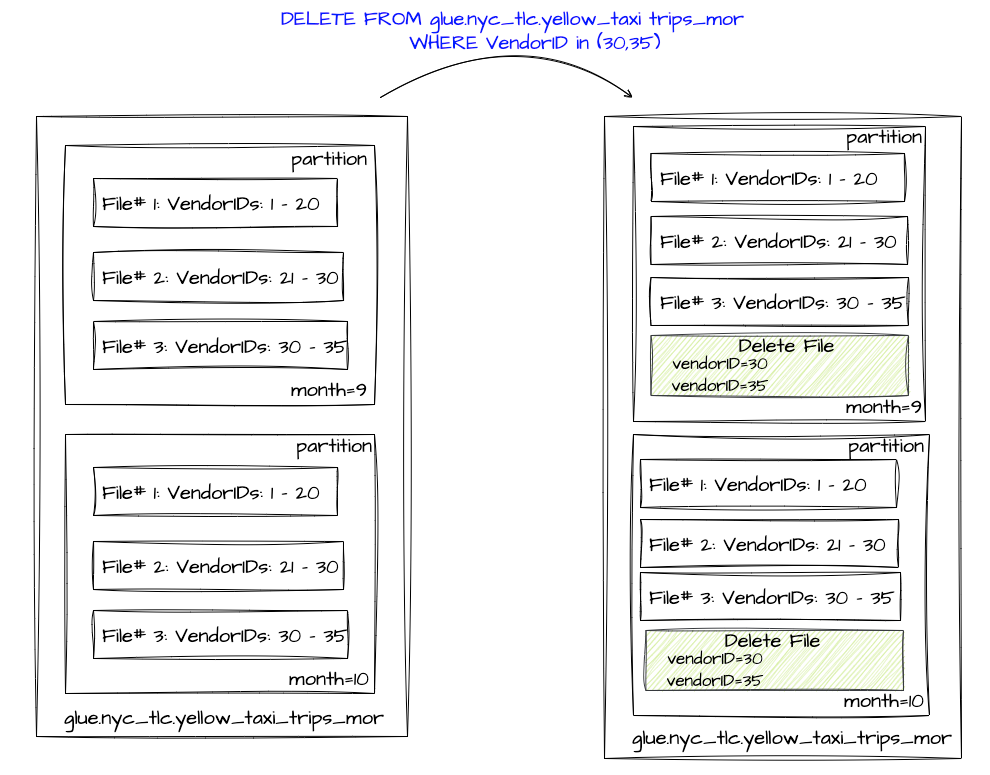
Equality Delete Files
Equality Delete Files stores the value of one or more columns of the deleted records. These column values are stored based on the condition used while deleting these records.
Delete Files are only supported by Iceberg v2 tables.
When I started understanding Delete files, the most curious question that I got was "How can I choose or configure that my table should use Positional or Euality Delete file while handling row-level updates?"
Turned out, there is no way as of now that lets you choose as a user for a specific Delete File type. It depends on how the DeleteFile Interface is implemented in the engine that is being used.
Alrighty, finally as now we know about delete files, let's take a look at the next approach and then off to the understanding it in code.
Merge-on-Read
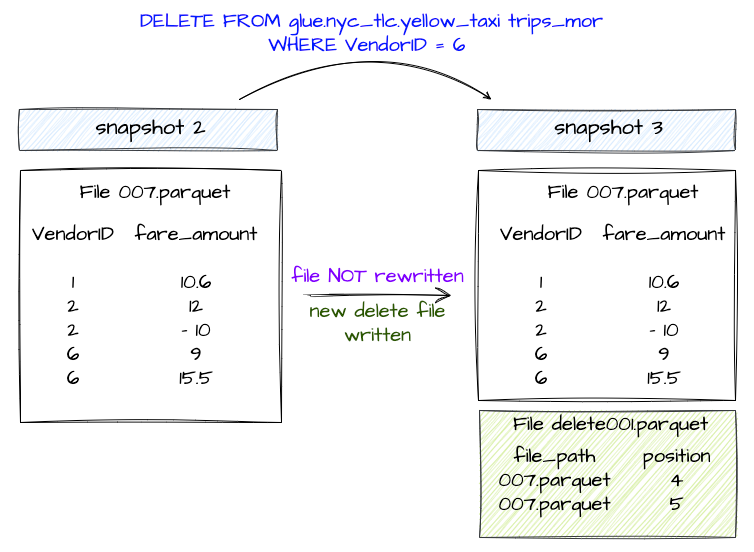
In this approach, update or delete operations on the Iceberg Table, the existing data files are not rewritten. Instead, a delete file is generated that keeps track of which records need to be ignored.
In case of deleting records, the record entries are listed in a Delete File.
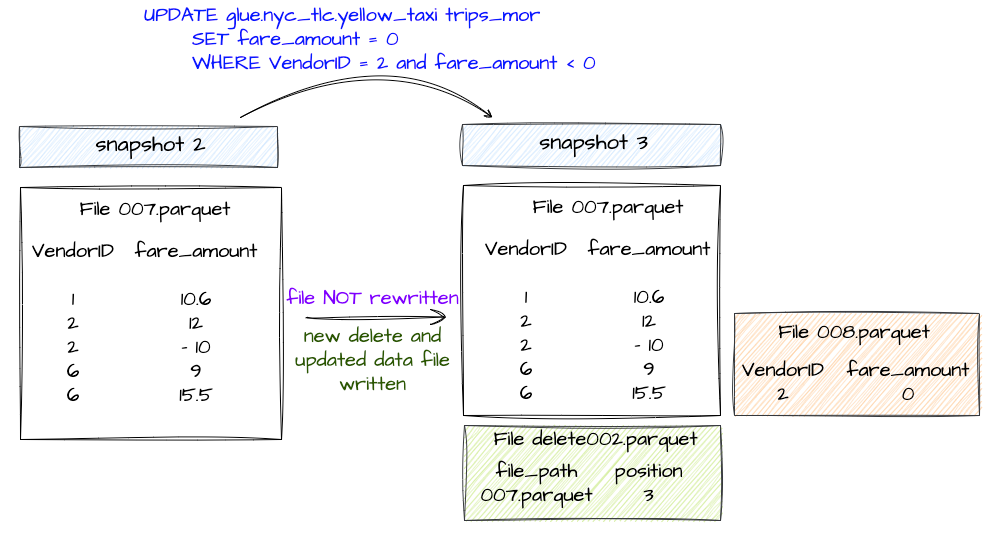
In case of updating records:
- The records to be updated are listed in a delete file.
- A new data file is created that contains only the updated records.
Configuring COW and MOR
Configuring COW or MOR for particular transactions is as simple as mentioning these in the table properties.
Keep in mind that these properties are the specifications and whether these work as expected or not depends on whether a query engine that is being used honors these or not. If not, you might end up in unexpected results.
Properties for configuring
- write.delete.mode : Approach to use for delete transactions
- write.update.mode: Approach to use for update transactions
- write.merge.mode: Approach to use for merge transactions
These table properties can be defined during the creation of a table or can be added to a table using ALTER statement.
CREATE TABLE catalog.db.sample_table (
vendorID int,
fare_amount double
) TBLPROPERTIES (
'write.delete.mode'='copy-on-write',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read'
) USING iceberg;Configuring properties during table creation
ALTER TABLE catalog.db.sample_table SET TBLPROPERTIES (
'write.delete.mode'='merge-on-read',
'write.update.mode'='copy-on-write',
'write.merge.mode'='copy-on-write'
);Configuring properties using ALTER statement
When to use which approach?
Before we get into when to use which approach, it's important to understand the pros and cons of using both COW and MOR and how these impact the read and write speed of the table.
Here's an idea to develop a quick intuition about read and write performance:
It's faster to read from a table if the query engine doesn't have to read lots of file and doesn't have to reconcile or do any additional work while reading the data.
It's faster to write into a table if query engine has to write less data.
Now based on this, let's see:
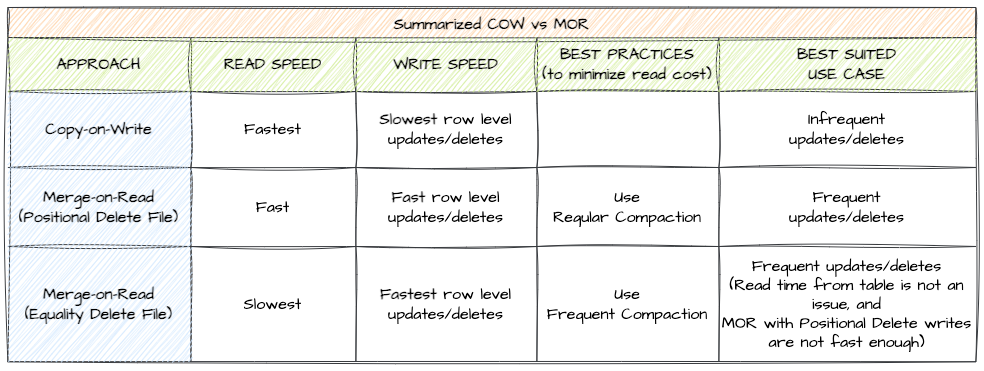
COW:
In case of row-level deletes/updates, it rewrites the entire file even if there is a single record is impacted.
More data needs to be written that causes slower row-level Updates/Deletes.
Data is read without reconciling. It writes any deleted or updated files, resulting in faster reads.
MOR:
In case of row-level deletes/updates, it avoids rewriting the entire data file.
It writes only the Delete File along with the updated data file in case of Updates i.e. basically writing less data and hence faster writes.
Data is read along with reconciling any deleted or updated files, resulting in slower reads.
Here's the summarization of everything we have discussed in this
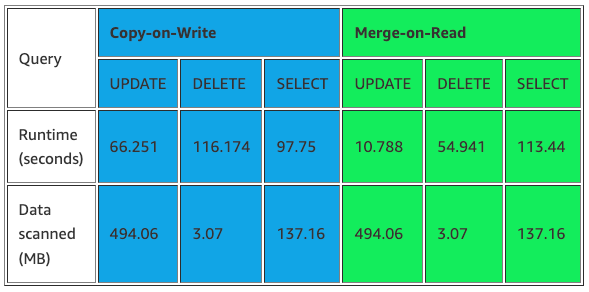
As for the performance of both of these approaches, here are some numbers provided by AWS on a blog, where they have run different row-level updates on 47.4GB of data multiple times.
That's it for all the concepts that you need to know.
The next section is about how you see these updates/deletes in the Iceberg metadata table in the case of both COW and MOR approaches. We will also see how to check how many delete or data files have been added/removed after both the DELETE and UPDATE operation along with how the data is stored in Delete Files in case of MOR.
COW/MOR Code Example
If you have decided to read this section, I would strongly recommend that you be familiar with Apache Iceberg Table Architecture.
If you are not familiar with or even need a quick refresher on Iceberg table architecture. You can give it a quick read here.
Setting up the environment
I will be using a Jupyter Notebook on AWS EMR 6.15 here, which uses AWS Glue Catalog as metadata store for both Hive Table and Spark Table metadata.
%%configure
{
"conf": {
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"spark.sql.catalog.glue": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.glue.catalog-impl":"org.apache.iceberg.aws.glue.GlueCatalog",
"spark.sql.catalog.glue.io-impl":"org.apache.iceberg.aws.s3.S3FileIO",
"spark.sql.catalog.glue.warehouse":"s3://aws-blog-post-bucket/glue/warehouse"
}
}Configuring Spark Session in EMR Notebook
If you are interested in understanding the configuration for Iceberg, you can check this blog post.
Creating 2 Iceberg Tables with the same data
I am using the NYC Yellow Taxi Trips data for Sep and Oct 2023. This can be found here.
from pyspark.sql.functions import lit, col
# Reading NYC Yellow Taxi Data
data_bucket = "aws-blog-post-bucket"
raw_data_path = f"s3://{data_bucket}/raw_data/nyc_tlc"
yellow_sep_df = spark.read.format("parquet").load(f"{raw_data_path}/yellow/sep2023/")
yellow_oct_df = spark.read.format("parquet").load(f"{raw_data_path}/yellow/oct2023/")
# Creating month and year column
yellow_sep_df = yellow_sep_df.withColumn("month", lit(9)) \
.withColumn("year", lit(2023))
yellow_oct_df = yellow_oct_df.withColumn("month", lit(10)) \
.withColumn("year", lit(2023))
yellow_df = yellow_sep_df.unionByName(yellow_oct_df)
yellow_df.groupBy("VendorID","month").count().show()
yellow_df.groupBy("VendorID").count().show()Reading data into dataframe
+--------+-----+-------+
|VendorID|month| count|
+--------+-----+-------+
| 1| 9| 731968|
| 2| 9|2113902|
| 6| 9| 852|
| 2| 10|2617320|
| 1| 10| 904463|
| 6| 10| 502|
+--------+-----+-------+Different VendorID with record count
# Creating 2 tables with same data
cow_table = "glue.blogs_db.yellow_taxi_trips_cow"
mor_table = "glue.blogs_db.yellow_taxi_trips_mor"
yellow_df.writeTo(cow_table).partitionedBy("year", "month").using("iceberg") \
.tableProperty("format-version", "2") \
.tableProperty("write.parquet.compression-codec", "snappy") \
.create()
yellow_df.writeTo(mor_table).partitionedBy("year", "month").using("iceberg") \
.tableProperty("format-version", "2") \
.tableProperty("write.parquet.compression-codec", "snappy") \
.create()Creating 2 tables with the data present in the dataframe
Setting up COW and MOR table properties for tables
spark.sql(f"""ALTER TABLE {cow_table} SET TBLPROPERTIES (
'write.delete.mode'='copy-on-write',
'write.update.mode'='copy-on-write',
'write.merge.mode'='copy-on-write'
)""")
spark.sql(f"""ALTER TABLE {mor_table} SET TBLPROPERTIES (
'write.delete.mode'='merge-on-read',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read'
)""")ALTER TABLE for adding COW and MOR table properties
Delete Operation on Iceberg Table
Let's perform the delete operations and look into the metadata tables for cow_table and mor_table
# Performing delete operation on COW Table
spark.sql(f"DELETE from {cow_table} where VendorId=6")Deleting all the records with VendorID = 6 on table with COW properties
# Performing delete operation on MOR Table
spark.sql(f"DELETE from {mor_table} where VendorId=6")Deleting all the records with VendorID = 6 on table with MOR properties
As per what we have learned about COW and MOR, COW rewrites the data file and MOR writes a Delete File that records the data file path and the exact position of the deleted record in the table.
Let's look into the Iceberg metadata tables to check these.
Analyzing Metadata tables after the DELETE operation
If you are new to Iceberg Metadata Tables, here is a short detail of the tables that we will be using in this section.
- Every write operation (insert/delete/update/merge) on an Iceberg Table creates a new snapshot for the table.
- The snapshot lineage and what operation has added a particular snapshot can be seen in
snapshotsmetadata table. - All the details of the file added and deleted within a particular snapshot can be seen in
manifeststable. - All the currently used data files for a table can be seen in
filestable.
COW Table Analysis
# Get the latest_snapshot_id from cow_table
spark.sql(f"select * from {cow_table}.snapshots").orderBy(col("committed_at").desc()).drop("summary").show(truncate=False)Looking for the latest snapshot_id for the cow_table
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+
|committed_at |snapshot_id |parent_id |operation|manifest_list |
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+
|2024-01-24 06:32:57.435|1999244325536185772|6487859664670042782|overwrite|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_cow/metadata/snap-1999244325536185772-1-927d13a0-7032-42d5-84db-12604090ecc0.avro|
|2024-01-24 06:29:54.142|6487859664670042782|null |append |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_cow/metadata/snap-6487859664670042782-1-94817dc8-e5f0-42fe-b14c-c6e72a4f3c39.avro|
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+snapshots table output
# checking the files added or deleted with latest snapshot_id
latest_snapshot_id = 1999244325536185772
spark.sql(f"select * from {cow_table}.manifests where added_snapshot_id={latest_snapshot_id}").drop("partition_summaries").show(truncate=False)Checking the details of added and deleted files count from manifest table
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+
|content|path |length|partition_spec_id|added_snapshot_id |added_data_files_count|existing_data_files_count|deleted_data_files_count|added_delete_files_count|existing_delete_files_count|deleted_delete_files_count|
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_cow/metadata/927d13a0-7032-42d5-84db-12604090ecc0-m1.avro|9009 |0 |1999244325536185772|2 |0 |0 |0 |0 |0 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_cow/metadata/927d13a0-7032-42d5-84db-12604090ecc0-m0.avro|10054 |0 |1999244325536185772|0 |5 |2 |0 |0 |0 |
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+manifests table output
The interesting fields to look in the above output are content added_data_files_count , deleted_data_files_count , and added_delete_files_count .
This shows that the data files are rewritten when using the COW approach.
MOR Table Analysis
# Get the latest_snapshot_id from mor_table
spark.sql(f"select * from {mor_table}.snapshots").orderBy(col("committed_at").desc()).drop("summary").show(truncate=False)Looking for the latest snapshot_id for the mor_table
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+
|committed_at |snapshot_id |parent_id |operation|manifest_list |
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+
|2024-01-24 06:33:04.833|799231277590704241 |8771378503908813917|overwrite|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/snap-799231277590704241-1-cb68448a-3cc0-4561-8b56-0f4dfa7ffd89.avro |
|2024-01-24 06:30:05.899|8771378503908813917|null |append |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/snap-8771378503908813917-1-fcc81a15-06ee-49e4-b305-de553b5a224d.avro|
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+snapshots table output
# checking the files added or deleted
latest_snapshot_id = 799231277590704241
spark.sql(f"select * from {mor_table}.manifests where added_snapshot_id = {latest_snapshot_id}").drop("partition_summaries").show(truncate=False)Checking the details of added and deleted files count from manifest table
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+
|content|path |length|partition_spec_id|added_snapshot_id |added_data_files_count|existing_data_files_count|deleted_data_files_count|added_delete_files_count|existing_delete_files_count|deleted_delete_files_count|
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+
|1 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/cb68448a-3cc0-4561-8b56-0f4dfa7ffd89-m0.avro|8464 |0 |799231277590704241|0 |0 |0 |2 |0 |0 |
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+manifest table output
Now if you look at the content column in the output, there are 2 possible values 0 and 1 .
In the manifest table,
content=0represents the manifest files that track data files, andcontent=1represents the manifest files that track the delete files.
If you look at the values of added_data_files_count and added_delete_files_count it's 0 and 1 respectively.
This shows the latest snapshot that was created after delete operation has just added Delete Files and no data files are rewritten.
Another interesting thing to look for MOR is the data present in files table.
spark.sql(f"select content, file_path, file_format, partition,record_count from {mor_table}.files").show(truncate=False)Looking into files table
+-------+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------+------------+
|content|file_format|file_path |record_count|
+-------+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------+------------+
|0 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00001-41-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |1048576 |
|0 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00004-44-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |1048576 |
|0 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00006-46-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |749570 |
|0 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00009-49-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |1048576 |
|0 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00011-51-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |1048576 |
|0 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00013-53-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |1048576 |
|0 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00015-55-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |376557 |
|1 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00000-71-902451fb-4e65-4817-b1ae-ea3a96f8eec8-00001-deletes.parquet |852 |
|1 |PARQUET |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00000-71-902451fb-4e65-4817-b1ae-ea3a96f8eec8-00002-deletes.parquet|502 |
+-------+-----------+----------------------------------------------------------------------------------------------------------------------------------------------------+------------+files table output
In the files table,
content =0represents a Data File,
content =1represents a Positional Delete File,
content =2represents an Equality Delete File.
As the content column in the table output has 1, this shows that Spark has created a Positional Delete Files. Also if you look into the file_path it shows that both the delete files created are in different partitions.
Let's take a look into one of these Positional Delete Files content.
# Checking contents in delete file
delete_file_path = "s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00000-71-902451fb-4e65-4817-b1ae-ea3a96f8eec8-00001-deletes.parquet"
delete_file_df = spark.read.parquet(delete_file_path)
delete_file_df.show(5,truncate=False)Looking into the contents of a Positional Delete File
+-------------------------------------------------------------------------------------------------------------------------------------------+------+
|file_path |pos |
+-------------------------------------------------------------------------------------------------------------------------------------------+------+
|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00006-46-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet|609427|
|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00006-46-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet|610008|
|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00006-46-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet|610045|
|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00006-46-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet|610046|
|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00006-46-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet|610091|
+-------------------------------------------------------------------------------------------------------------------------------------------+------+Contents of a Positional Delete File
As we saw previously in the Delete File section, Positional Delete files store the data file path and position of the deleted record in the corresponding data file. It can be seen in the output above.
Update Operation On Iceberg Table
As in case of the COW approach, it just rewrites the data file in both the Delete/Update Operation, nothing interesting to look into.
We will perform an update operation on the table with MOR properties enabled.
# Performing an update operation
spark.sql(f"update {mor_table} set fare_amount = 0 where VendorID=2 and fare_amount < 0")Updating all the fare_amount for all the records with VendorID = 2 and has negative fare_amount
Analyzing Metadata tables after the UPDATE operation
# Get the latest_snapshot_id from mor_table
spark.sql(f"select * from {mor_table}.snapshots").orderBy(col("committed_at").desc()).drop("summary").show(truncate=False)Getting latest snapshot_id after UPDATE Operation
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+
|committed_at |snapshot_id |parent_id |operation|manifest_list |
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+
|2024-01-24 06:44:48.175|2049488298809185761|799231277590704241 |overwrite|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/snap-2049488298809185761-1-38007485-31ae-443d-b10a-e3eecdbc27ba.avro|
|2024-01-24 06:33:04.833|799231277590704241 |8771378503908813917|overwrite|s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/snap-799231277590704241-1-cb68448a-3cc0-4561-8b56-0f4dfa7ffd89.avro |
|2024-01-24 06:30:05.899|8771378503908813917|null |append |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/snap-8771378503908813917-1-fcc81a15-06ee-49e4-b305-de553b5a224d.avro|
+-----------------------+-------------------+-------------------+---------+--------------------------------------------------------------------------------------------------------------------------------------+snapshots table output after UPDATE Operation
# checking the files added or deleted with latest snapshot_id
latest_snapshot_id = 2049488298809185761
spark.sql(f"select * from {mor_table}.manifests where added_snapshot_id = {latest_snapshot_id}").drop("partition_summaries").show(truncate=False)Checking the details of added and deleted files count from manifest table for latest_snapshot_id
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+
|content|path |length|partition_spec_id|added_snapshot_id |added_data_files_count|existing_data_files_count|deleted_data_files_count|added_delete_files_count|existing_delete_files_count|deleted_delete_files_count|
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/38007485-31ae-443d-b10a-e3eecdbc27ba-m0.avro|8943 |0 |2049488298809185761|2 |0 |0 |0 |0 |0 |
|1 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/metadata/38007485-31ae-443d-b10a-e3eecdbc27ba-m1.avro|8379 |0 |2049488298809185761|0 |0 |0 |2 |0 |0 |
+-------+--------------------------------------------------------------------------------------------------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+------------------------+---------------------------+--------------------------+If you look at added_data_files_count and added_delete_files_count , there are 2 data and delete files have been added. The Delete Files in this case include the file path and position of the updated records and the data files include the records with updated value.
To easily identify these files in files table, let's see first how many records have been impacted.
# Checking the number of records that would have been updated as part of update operation
yellow_df.filter((col("fare_amount") < 0) & (col("VendorID") == 2)).groupBy("VendorID", "month").count().show()No. of records impacted as part of the UPDATE operation on mor_table
+--------+-----+-----+
|VendorID|month|count|
+--------+-----+-----+
| 2| 9|29562|
| 2| 10|37099|
+--------+-----+-----+Updated records after the UPDATE operation in mor_table
Let's look in files table.
# checking file tables after UPDATE operation on mor_table
spark.sql(f"select content, file_path, file_format, partition,record_count from {mor_table}.files").show(truncate=False)Checking files table after the delete operation to see the newly added Data file and Delete file
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------+-----------+----------+------------+
|content|file_path |file_format|partition |record_count|
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------+-----------+----------+------------+
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00001-88-630c6981-9422-40c3-acbf-2efeccf058e7-00001.parquet |PARQUET |{2023, 10}|37099 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00002-89-630c6981-9422-40c3-acbf-2efeccf058e7-00001.parquet |PARQUET |{2023, 9} |29562 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00001-41-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |PARQUET |{2023, 9} |1048576 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00004-44-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |PARQUET |{2023, 9} |1048576 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00006-46-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |PARQUET |{2023, 9} |749570 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00009-49-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |PARQUET |{2023, 10}|1048576 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00011-51-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |PARQUET |{2023, 10}|1048576 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00013-53-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |PARQUET |{2023, 10}|1048576 |
|0 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00015-55-131e5ffa-a9ce-4b67-96d7-f49cae976d4d-00001.parquet |PARQUET |{2023, 10}|376557 |
|1 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00000-87-630c6981-9422-40c3-acbf-2efeccf058e7-00001-deletes.parquet|PARQUET |{2023, 10}|37099 |
|1 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00003-90-630c6981-9422-40c3-acbf-2efeccf058e7-00001-deletes.parquet |PARQUET |{2023, 9} |29562 |
|1 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=9/00000-71-902451fb-4e65-4817-b1ae-ea3a96f8eec8-00001-deletes.parquet |PARQUET |{2023, 9} |852 |
|1 |s3://aws-blog-post-bucket/blogs_db/yellow_taxi_trips_mor/data/year=2023/month=10/00000-71-902451fb-4e65-4817-b1ae-ea3a96f8eec8-00002-deletes.parquet|PARQUET |{2023, 10}|502 |
+-------+----------------------------------------------------------------------------------------------------------------------------------------------------+-----------+----------+------------+Output from files table after the UPDATE operation on mor_table
Row #1 and Row#2 in the above output show the data files added, and Row #10 and #11 show the new delete files added. Now if we look at the record_count and partition column across these rows, we can see the number of records in data and delete files are the same across each partition.
That's it for this one folks..!!! 😊
Now you know how to identify changes in case of COW and MOR approaches in the tables via metadata table also.
See you in the next one..! 🚀
If it has added any value to you and want to read more content like this, subscribe to the newsletter, it's free of cost and I will make sure every post is worth your time and you get to learn something new.





Member discussion