Enhancing Spark Job Performance with Multithreading

Every engineer who has worked on Spark understands the criticality of using the cluster resources efficiently and how to use these resources to make a Spark job run faster.
This blog post will examine how to leverage Python Multithreading to submit independent jobs in parallel. When I say "independent job", think of any use case where you submit queries from the driver in a for loop. Some such use cases are:
- backfilling tables (in case of sequential partition writes),
- running some DQ queries independently of each other or
- getting records count and other column stats of all the tables in your data pipeline for auditing/logging purposes.
In these scenarios, instead of submitting jobs from the driver sequentially (using a for loop), we can use Multithreading to submit them so they run all at once. This enables a Spark Job to run faster and utilize the cluster resources efficiently.
To understand how to leverage multithreading in your Spark Jobs, let's take a simple example: We want to get the record count of all the tables in our data pipeline and write it into a control table.
Sequential Approach
The naive approach to get the count is running a for-loop to get the count like this and then write into the control table:
# List of tables
TABLES = ['db1.table1', 'db1.table2',
'db2.table3', 'db2.table4',
'db3.table5', 'db3.table6']
# List to keep the dictionary of table_name and respective count
table_count = []
# function to get the table records count.
def get_count(table: str) -> dict:
count_dict = {}
count_dict['table_name'] = table
try:
count = spark.read.table(table).count()
count_dict['count'] = count
except Exception:
count_dict['count'] = 0
return count_dict
def main():
for table in TABLES:
table_count.append(get_count(table))
if __name__ == "__main__":
main()
# Creating dataframe from list
count_df = spark.createDataFrame(table_count)\
.withColumn("date", datetime.now().date())
# writing into the table
count_df.coalesce(1).write.insertInto("control_db.counts_table")
Sequential count fetcher
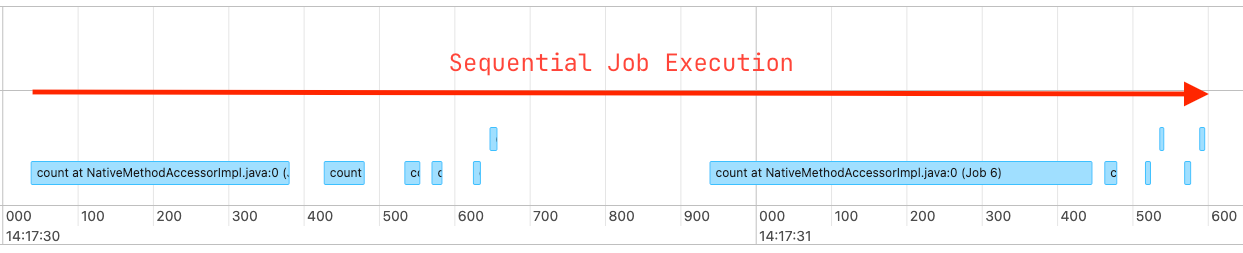
This will work as expected and give us the desired results, but this is not an efficient way of doing this. A few reasons for this are getting counts of tables aren't dependent on each other, and each count job is being submitted in sequence, so until and unless the currently submitted job is not completed, it's blocking the next job submission. This results in running Spark Job longer than expected, consuming cluster resources but not using them efficiently.
This will look like this on Spark UI:
Leveraging Multithreading
As we are intelligent engineers and we want our jobs to run faster with better resource utilization, here is how we can leverage multithreading to optimize the same job run.
We will be using ThreadPoolExecutor from concurrent.futures package instead of multiprocessing.pool.ThreadPool. This is because ThreadPoolExecutor is newer and has a simpler API, and it's also recommended in the documentation here.
We are going to update the main() function code to use TheadPoolExecutor
Using ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor
# List of tables
TABLES = ['db1.table1', 'db1.table2',
'db2.table3', 'db2.table4',
'db3.table5', 'db3.table6']
# function to get the table records count.
def get_count(table: str) -> dict:
...
# same as before
return count_dict
# Code implementation using ThreadPoolExecutor
def main():
counts = []
with ThreadPoolExecutor(max_workers=6) as executor:
counts = executor.map(get_count, TABLES)
return counts
if __name__ == "__main__":
table_count = main()
# Creating dataframe from list
count_df = spark.createDataFrame(table_count)\
.withColumn("date", datetime.now().date())
# writing into the table
count_df.coalesce(1).write.insertInto("control_db.counts_table")Count fetcher using ThreadPoolExecutor
That's it...?!?! Yes. I know, right? This is the same number of lines of code as for loop, but it does so much better.

This is how it looks in Spark UI:

Here are a few things that you should know about while leveraging this technique:
- Number of parallel jobs submission are dependent on the provided
max_workerparameter while definingThreadPoolExecutorand number of cores present in the driver node. - If
max_executorsparameter is not given, the default value is taken asmin(32, (os.process_cpu_count() or 1) + 4). It can be seen here. - Only the job submission is happening in parallel here, how long does a job take to complete still depends on the Spark executor configurations provided during
spark-submit
Although this is so short and simple, there is a drawback in this i.e. there is no way to debug this code easily if something fails, especially when you are submitting a whole lot of queries.
Don't be that guy who says as long as it doesn't fail. 😄

Here's how we can rewrite the main method using ThreadPoolExecutor that can be easier to debug in case of any issues.
# With exception hadling to make debugging easier
from concurrent.futures import ThreadPoolExecutor, as_compeleted
def main(TABLES: list) -> None:
"""Main method to submit count jobs in parallel.
Args:
TABLES (list): list of table name.
Raises:
e: Exception in case of any failures
"""
with ThreadPoolExecutor(max_workers=6) as executor:
to_do_map = {}
for table in TABLES:
# Submitting jobs in parallel
future = executor.submit(get_count, table)
print(f"scheduled for {table}: {future}")
to_do_map[future] = table
done_iter = as_completed(to_do_map)
for future in done_iter:
try:
count = future.result()
print("result: ", count)
count_list.append(count)
except Exception as e:
raise emain() code for better Exception Handling
Explanation:
executor.submitschedules theget_count()to be executed, and returns afuturerepresenting the pending operation.concurrent.futures.Futureis an instance ofFutureclass represents a deferred computation that may or may not have been completed.as_completetakes an iterable of futures and returns an iterator that yields futures as they are completed.future.result()get the results of the completed future. This where exceptions needs to be handled properly for better debugging in case of errors.
While trying to understand how this implementation works internally in Spark, here are some curious question that came to my mind:
Does GIL (Global Interpreter Lock) impact the parallelism in Spark like it does in regular Python code?
Well, the straightforward answer is NO, as we can see on the Spark UI, but now the question is WHY?!?
The answer is that Parallelization in PySpark is achieved by daemon.py calling os.fork() to create multiple worker processes. os.fork() is the same method that multiprocessing module in Python uses to spawn multiple processes, which GIL does not impact as each process has its own GIL.
When is daemon.py called in PySpark?
On a very high level, when we submit a job or call an action (like collect, count, etc.) on an RDD or DataFrame, Spark creates worker processes on the cluster. The daemon.py script runs these worker processes, which execute the tasks on the data.
The key functions of daemon.py are:
- launching and monitoring Python worker processes.
- facilitating communication between the Spark driver and the worker nodes, sending code and data back and forth.
- handling any exceptions or errors that occur during the execution of tasks.
This is all you need to know about utilizing multithreading to enhance your Spark Jobs.
Real World Example
The example mentioned in this post is pretty simple, but here's a real-world example where I have used to enhance the performance of multiple Spark Jobs. In a project, we developed a DQ check framework that filters out the bad records (based on certain criteria's) before they flow into our data pipeline. It's a collection of hundreds of queries defined across multiple sources stored in a DQ table where developers can introduce more DQ check queries as per the requirements.
Below are the screenshots from Spark UI of how it looked when queries were running in sequence and after it leveraged multithreading to run these queries.
As for the time reduction, time was reduced from around 20mins to 3mins.

for loop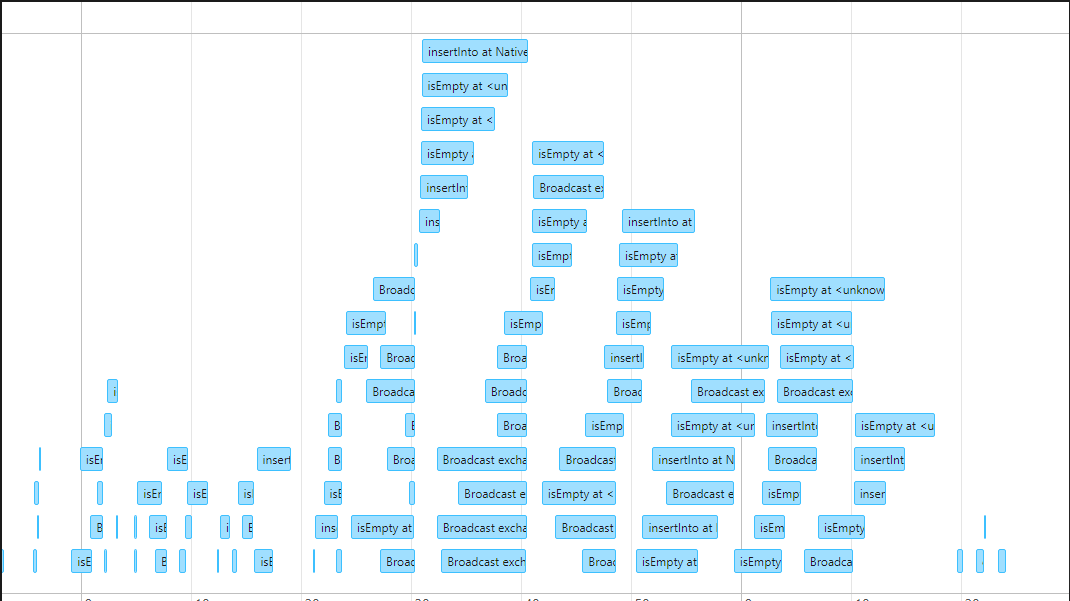
ThreadPoolExecutorCommon Pitfalls
With great power, comes great responsibility - this is so true in this use case also. Here are some pitfalls that you should avoid or atleast try to avoid:
- If you are running your Spark Application on client mode, be mindful how the
max_executorsparameter is set. You don't want to be hogging all the vCores of your cluster master nodes, especially when it's a shared cluster among multiple teams. - Submitting way too many jobs concurrently can result in high driver memory consumption.
- Exception handling is extremely important in such scenarios i.e. handling exception while calling
future.result()as this makes debugging easier and understand what exactly is causing the issue. - Beware while writing into a table concurrently, this might result in to
ConcurrentModificationerrors or unexpected results especially when you are doing a parititionOverwrite. Understanding how your table is partitioned can help avoiding unexpected errors and results.
That's it for this one..!!!
If it has added any value to you and want to read more content like this, subscribe to the newsletter, it's free of cost and I will make sure every post is worth your time.



Member discussion