EMRFS S3 Optimized Committer and Committer Protocol for Improving Spark Write Performance - Why and How?

Just writing a Spark job is not sufficient, knowing what it's doing under the hood is a secret sauce to make them run faster.
Knowing how your Spark job is writing the files behind the scenes can help you optimize the overall time the job takes to complete. OutputCommitters are the classes responsible for writing your data files into the storage. Based on which implementation of this class is being used while writing decide if it's committing data files via renaming the directories.
By the end of this blog post, you will be fully equipped with the skills to know if your Spark job is writing efficiently, how to optimize it by enabling EMRFS S3 Optimized Committers, and most importantly, how you can identify if these committers are working after enabling them.
This blog post will cover:
- What does Commit Protocol and Committing mean?
- What are EMRFS S3-optimized committer and EMRFS S3-optimized commit protocol?
- Why do we need EMRFS S3-optimized committer and committer protocol?
- How to enable these S3-optimized committers and when to use which one?
- How to check if these are working for your job after enabling them?
Let's start with demystify some buzzwords in this space like commit protocol and committing.
What is "the commit protocol"?
It’s the requirement on workers as to when their data is made visible, where, for a filesystem, “visible” means “can be seen in the destination directory for the query.” Also, it ensures that jobs and tasks either succeed or fail cleanly.
What does commit means?
Simply, it just means moving the task output from a temp directory to the specified output directory. When working with distributed filesystems, it’s achieved by renaming the directory.
What is EMRFS?
The EMR File System (EMRFS) is an implementation of HDFS that all Amazon EMR clusters use for reading and writing regular files from Amazon EMR directly to Amazon S3. EMRFS provides the convenience of storing persistent data in Amazon S3 for use with Hadoop while also providing features like data encryption.
Why do we need additional optimized committers and commit protocols for Object Storage?
In Object Storage like S3, committing data files using rename is horribly slow because renaming requires reading and writing an entire data file with a new name and deleting the previous one while in File Storage like HDFS it's just a metadata operation which is super fast compared to copying the entire data file.
Now as EMR uses EMRFS to read and write from Amazon S3, it provides EMRFS S3-optimized committer and EMRFS S3-optimized commit protocol that improves the write performance by avoiding the renaming operations done in Amazon S3 during Job and Task commit phases.
Before diving deeper into how this EMRF S3-optimized committer and commit protocol improves the write performance, we need to know what happens when a write is issued and what steps are used before the Job is finally committed.
Here's a very high-level overview of the same:
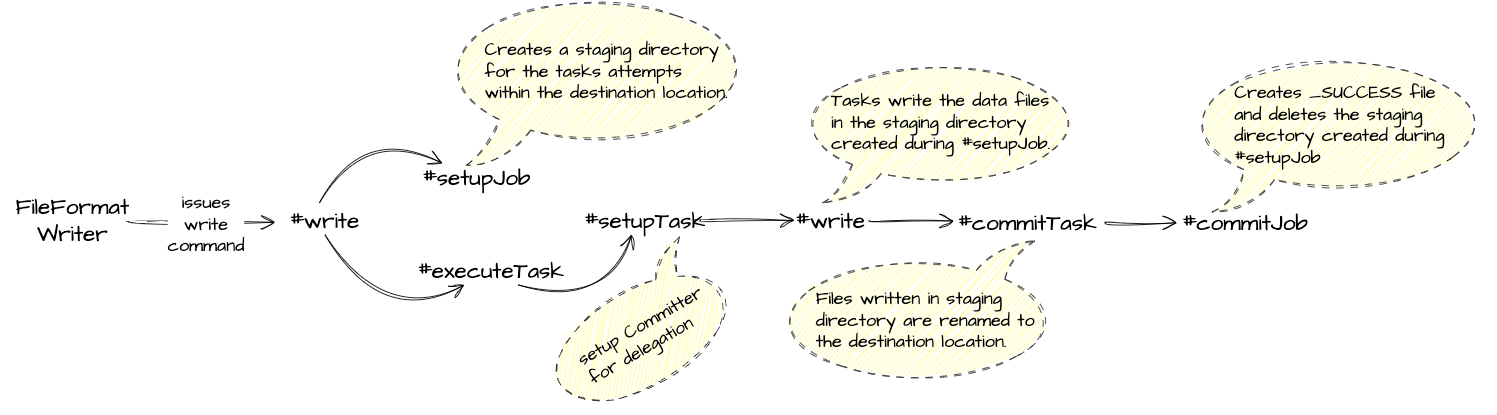
Now the above flow gives a very high-level overview of all the steps involved until the files are finally visible in the destination location. These steps are performed by multiple classes in the backend. We will build on top of it and see how things change within these steps once we use the EMRFS S3-optimized committer and commit protocol.
Internally committer protocols delegate their work to the committer that's being set up during the setupTask stage and which committer will be used depends on the protocol class implementation and configuration that is being passed to this class.
Introducing EMRFS S3-Optimized Committer and Commit Protocol
EMRFS S3-Optimized Committer and Commit Protocol are optimized for improving the write performance of files to Amazon S3 when using EMRFS by avoiding list and rename operations done in S3 during job and task commit phases.
Both of these use the transaction-like characteristics of S3 multipart uploads to avoid any rename operation and ensure files written by task attempts only appear in the job's output location upon the task commit.
Transaction-like characteristics of S3 multipart upload are mainly that the file is only available to read from S3 location only when all the parts of a file have been uploaded to S3.
By using multipart uploads to the job output location on task commit, task commit performance is improved over the default FileOutputCommitter V2 algorithm. This is mainly because in the FileOutputCommiter V2 algorithm during the task commit phase, the renaming of the file from staging directory to job output location is done, which is not required anymore due to the multipart uploads to job output location directly.
All the file listing operations are avoided because instead of listing the files in the job output or staging S3 location it uses HTTPS API calls to S3 URI for checking the files' status and the key counts, we will have a look into this in the later part of this blog.
Alrighty now that we know what causes the write performance to improve when using EMRFS S3-Optimized Committer and Commit Protocol, let's dive into these and see how can we check if these are working for Spark jobs.
EMRFS S3-Optimized Committer
It's an alternative OutputCommitter implementation. An OutputCommitter is an abstract class and ensures that a commit protocol is being used. This S3-Optimized Committer is available starting from EMR 5.19.0 and is enabled by default with EMR 5.20.0 and later.
We will be discussing here for the Parquet Tables but the requirement for other table formats can be seen in the docs.
Requirements
- Spark job uses Spark SQL, DataFrames, or Dataset to write files.
- Spark built-in file format support is used i.e.
spark.sql.hive.convertMetastoreParquetis set totrue. This is by default. - The target table is created using
USING parquetclause i.e. mainly that it's a Hive Parquet table or uses Hive Parquet Serde while reading writing from the table. - Spark job operations that write to a default partition location—for example,
${table_location}/k1=v1/k2=v2/ - Multipart uploads must be enabled for AWS EMR.
Spark must have configs:
spark.sql.parquet.fs.optimized.committer.optimization-enabledset totruespark.sql.hive.convertMetastoreParquetset totruespark.sql.parquet.output.committer.classset tocom.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitterspark.sql.sources.commitProtocolClassset toorg.apache.spark.sql.execution.datasources.SQLEmrOptimizedCommitProtocolororg.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol.partitionOverwriteModewhile overwriting the parquet dataset must bestaticas write option andspark.sql.sources.partitionOverwriteModeset tostatic.
Most of the spark configurations mentioned in the Requirements section are enabled by default. If you are not sure, the same can be checked using spark.conf.get("conf-key-name") from a Jupyter notebook running Spark kernel or from spark-shell running in EMR.
One of the most important thing to note here is that this committer work only in case ofpartitionOverwriteModeasstaticwhile writing into an S3 location or if you are loading a table then it works only fornon-partitionedHive metastore Parquet tables.
Now to understand how this write is optimized let's look into the case first where the optimized committer doesn't work. I will be using EMR 6.15 for the demo but you can use other versions starting from EMR 5.19.0
Optimization is disabled – S3-Optimized Commiter DOESN'T work
Default configuration for partitionOverwriteMode is set to STATIC.
%%configure
{
"conf": {
"spark.sql.sources.commitProtocolClass":"org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol",
"spark.sql.parquet.fs.optimized.committer.optimization-enabled": "false"
}
}Setting Optimization disabled
print(
spark.conf.get("spark.sql.sources.commitProtocolClass"),
spark.conf.get("spark.sql.sources.partitionOverwriteMode"),
spark.conf.get("spark.sql.parquet.fs.optimized.committer.optimization-enabled")
spark.conf.get("spark.sql.parquet.output.committer.class"),
spark.conf.get("spark.sql.hive.convertMetastoreParquet")
)Printing the required configuration
('org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol', 'STATIC', 'false', 'com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter','true')Configuration output being used in Job
-- can run this directly via Athena or using spark.sql
CREATE EXTERNAL TABLE `blogs_db.emr_committer_test_non_ptn`(
`id` int,
`dt` date
STORED AS PARQUET
LOCATION
's3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn'CREATE Statement for non-partitioned table
from pyspark.sql.functions import date_sub,col, lit
from datetime import datetime
#dataset = spark.range(0,1000).withColumn("id", col("id").cast("int")).withColumn("dt", lit(datetime.date(datetime.now())))
dataset = spark.range(0,500).withColumn("id", col("id").cast("int")).withColumn("dt", lit(datetime.date(datetime.now())))
dataset.show(5)Creating a dataset that needs to be inserted
+---+----------+
| id| dt|
+---+----------+
| 0|2024-02-10|
| 1|2024-02-10|
| 2|2024-02-10|
| 3|2024-02-10|
| 4|2024-02-10|
+---+----------+dataset output
# writing data into non partitioned Hive table with mode as overwrite
dataset.coalesce(1).write.insertInto("blogs_db.emr_committer_test_non_ptn", overwrite=True)Writing dataset into a non-partitioned table
Let's look into the log to see what happens under the hood when EMRFS S3-Optimized Committer is not working.
....
24/02/10 11:42:46 INFO SQLConfCommitterProvider: Getting user defined output committer class com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter
24/02/10 11:42:47 INFO EmrOptimizedParquetOutputCommitter: EMR Optimized Committer: DISABLED
24/02/10 11:42:47 INFO EmrOptimizedParquetOutputCommitter: Using output committer class org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
24/02/10 11:42:47 INFO FileOutputCommitter: File Output Committer Algorithm version is 2
24/02/10 11:42:47 INFO FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: true
....
24/02/10 11:42:48 INFO CodecPool: Got brand-new compressor [.snappy]
24/02/10 11:42:48 INFO TransportClientFactory: Successfully created connection to ip-172-31-10-208.ap-south-1.compute.internal/172.31.10.208:35115 after 2 ms (0 ms spent in bootstraps)
24/02/10 11:42:48 INFO CodeGenerator: Code generated in 304.471341 ms
24/02/10 11:42:49 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/_temporary/0/_temporary/attempt_202402101142404460199108560845936_0002_m_000000_2/part-00000-8f6f3dda-c4ac-4db5-961e-ada45934f61c-c000.snappy.parquet
24/02/10 11:42:50 INFO S3NativeFileSystem: rename s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/_temporary/0/_temporary/attempt_202402101142404460199108560845936_0002_m_000000_2/part-00000-8f6f3dda-c4ac-4db5-961e-ada45934f61c-c000.snappy.parquet s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/part-00000-8f6f3dda-c4ac-4db5-961e-ada45934f61c-c000.snappy.parquet using algorithm version 1
24/02/10 11:42:50 INFO FileOutputCommitter: Saved output of task 'attempt_202402101142404460199108560845936_0002_m_000000_2' to s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn
24/02/10 11:42:50 INFO SparkHadoopMapRedUtil: attempt_202402101142404460199108560845936_0002_m_000000_2: Committed. Elapsed time: 301 ms.
24/02/10 11:42:50 INFO Executor: Finished task 0.0 in stage 2.0 (TID 2). 2570 bytes result sent to driver
....
24/02/10 11:42:50 INFO FileFormatWriter: Start to commit write Job f94cb5e3-e01e-4586-917f-4b6ecfba1d10.
24/02/10 11:42:50 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/_SUCCESS
24/02/10 11:42:50 INFO FileFormatWriter: Write Job f94cb5e3-e01e-4586-917f-4b6ecfba1d10 committed. Elapsed time: 227 ms.
24/02/10 11:42:50 INFO FileFormatWriter: Finished processing stats for write job f94cb5e3-e01e-4586-917f-4b6ecfba1d10.
....INFO logs for optimization disabled
Here's a quick overview of what's happening under the hood when the optimization is disabled:
_temporary/0/_temporary/attempt_202402101142404460199108560845936_0002_m_000000_2path is created inside the job output location i.e. table paths3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn- Data is written into EMR local and then multipart uploaded into this temporary location.
- Sequential renaming of files happens from temp location to job output location which is an expensive operation in an Object Storage like AWS S3.
_SUCCESSfile is created in the job output location during the final job is being committed.FileOutputCommitteris used when optimization is disabled.
Using EMRFS S3-Optimized Committer i.e. Optimization enabled and using SQLHadoopMapReduceCommitProtocol with dynamicOverwrite set to static for a non-partitioned table – Commiter Works
Default configuration forspark.sql.parquet.fs.optimized.committer.optimization-enabledistruestarting from EMR 5.20.0
%%configure
{
"conf": {
"spark.sql.sources.commitProtocolClass":"org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol",
"spark.sql.sources.partitionOverwriteMode": "static"
}
}Configuration when S3 Optimized Committer works.
print(
spark.conf.get("spark.sql.sources.commitProtocolClass"),
spark.conf.get("spark.sql.sources.partitionOverwriteMode"),
spark.conf.get("spark.sql.parquet.fs.optimized.committer.optimization-enabled")
spark.conf.get("spark.sql.parquet.output.committer.class"),
spark.conf.get("spark.sql.hive.convertMetastoreParquet")
)
Printing all the required configurations
('org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol', 'static', 'true', 'com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter','true')Output of all the configurations
# Creating dataset
from pyspark.sql.functions import date_sub,col, lit
from datetime import datetime
dataset = spark.range(0,500).withColumn("id", col("id").cast("int")).withColumn("dt", date_sub(lit(datetime.date(datetime.now())), lit(4)))
dataset.show(5)Creating a dataset that needs to be inserted into a non-partitioned table
+---+----------+
| id| dt|
+---+----------+
| 0|2024-02-04|
| 1|2024-02-04|
| 2|2024-02-04|
| 3|2024-02-04|
| 4|2024-02-04|
| 5|2024-02-04|
+---+----------+dataset output
# writing data into non partitioned Hive table with mode as overwrite
dataset.coalesce(1).write.insertInto("blogs_db.emr_committer_test_non_ptn", overwrite=True)Writing data into the output table
Let's take a peek inside the logs in the case when EMRFS S3-Optimized Committer is working
.....
24/02/07 14:46:37 INFO EmrOptimizedParquetOutputCommitter: EMR Optimized Committer: ENABLED
24/02/07 14:46:37 INFO EmrOptimizedParquetOutputCommitter: Using output committer class org.apache.hadoop.mapreduce.lib.output.FileSystemOptimizedCommitter
24/02/07 14:46:37 INFO FileOutputCommitter: File Output Committer Algorithm version is 2
24/02/07 14:46:37 INFO FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: true
24/02/07 14:46:37 INFO SQLConfCommitterProvider: Using output committer class com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter
24/02/07 14:46:37 INFO FileSystemOptimizedCommitter: Created staging directory at s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn named 0_attempt_20240207144637830028175290150178_0001_m_000000_1 when getting work path
.....
24/02/07 14:46:37 INFO StagingUploadPlanner: Creating a new staged file 's3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/.emrfs_staging_0_attempt_20240207144637830028175290150178_0001_m_000000_1/part-00000-25686dc0-ff93-4fb6-a679-ce352bb921a1-c000.snappy.parquet' with destination key 'blogs_db/emr_committer_test_non_ptn/part-00000-25686dc0-ff93-4fb6-a679-ce352bb921a1-c000.snappy.parquet'
24/02/07 14:46:37 INFO CodecPool: Got brand-new compressor [.snappy]
24/02/07 14:46:38 INFO CodeGenerator: Code generated in 40.115189 ms
24/02/07 14:46:38 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/part-00000-25686dc0-ff93-4fb6-a679-ce352bb921a1-c000.snappy.parquet
24/02/07 14:46:39 INFO MultipartUploadOutputStream: uploadPart: partNum 1 of 's3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/part-00000-25686dc0-ff93-4fb6-a679-ce352bb921a1-c000.snappy.parquet' from local file '/mnt/s3/emrfs-7576990015875678729/0000000000', 2710 bytes in 44 ms, md5: jDkovLJaVXt5Ye0cUKIO+A== md5hex: 8c3928bcb25a557b7961ed1c50a20ef8
24/02/07 14:46:39 INFO FileSystemOptimizedCommitter: Publishing staging directory at s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn named 0_attempt_20240207144637830028175290150178_0001_m_000000_1
24/02/07 14:46:40 INFO DefaultMultipartUploadDispatcher: Completed multipart upload of 1 parts 2710 bytes
24/02/07 14:46:40 INFO InMemoryStagingDirectory: Completed deferred upload of 's3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/part-00000-25686dc0-ff93-4fb6-a679-ce352bb921a1-c000.snappy.parquet' under staging directory at 's3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/.emrfs_staging_0_attempt_20240207144637830028175290150178_0001_m_000000_1'
24/02/07 14:46:40 INFO DeferredUploadStatistics: Completed 1 deferred upload(s) under staging directory at 's3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/.emrfs_staging_0_attempt_20240207144637830028175290150178_0001_m_000000_1' (upload completion deferral time (msec): min=96, avg=96, median=96, max=96; file size (bytes): min=2710, avg=2710, median=2710, max=2710)
24/02/07 14:46:40 INFO FileSystemOptimizedCommitter: Deleting staging directory at s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn named 0_attempt_20240207144637830028175290150178_0001_m_000000_1
24/02/07 14:46:40 INFO SparkHadoopMapRedUtil: attempt_20240207144637830028175290150178_0001_m_000000_1: Committed. Elapsed time: 78 ms.
24/02/07 14:46:40 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 2570 bytes result sent to driver
....
24/02/07 14:46:40 INFO FileFormatWriter: Start to commit write Job f17dd9ba-6b5d-4f50-b828-a23dc98f1449.
24/02/07 14:46:40 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn/_SUCCESS
24/02/07 14:46:40 INFO FileFormatWriter: Write Job f17dd9ba-6b5d-4f50-b828-a23dc98f1449 committed. Elapsed time: 86 ms.
24/02/07 14:46:40 INFO FileFormatWriter: Finished processing stats for write job f17dd9ba-6b5d-4f50-b828-a23dc98f1449.
.....INFO Logs of the application when EMRFS S3-Optimized Committer is working
On looking into the logs we can observe:
- There is no
_temporary/0.../directory created inside the job output location i.e. table S3 location locations3://aws-blog-post-bucket/blogs_db/emr_committer_test_non_ptn - Only a staging directory is created i.e.
.emrfs_staging_0_attempt_20240207144637830028175290150178_0001_m_000000_1 - The data after being written into the EMR local
/mnt/s3/emrfs-7576990015875678729/is directly being uploaded to the table S3 location and_SUCCESSfile is created within the same. - There is NO renaming of files at all and that's where the actual difference in write performance can be observed compared to the previous case where the committer was not working.
- When the optimization is enabled, the OutputCommitter that is being used is
FileSystemOptimizedCommitterinstead ofFileOutputCommitter.
We have seen so far how write performance can be improved while writing into non-partitioned tables using EMRFS S3-Optimized Committers but what if we want to improve the performance in case of overwriting a partitioned table and that's where the EMRFS S3-Optimized Commit Protocol comes into picture.
EMRFS S3-Optimized Commit Protocol
The EMRFS S3-optimized commit protocol is an alternative FileCommitProtocol implementation that is optimized for writing files with Spark dynamic partition overwrite to Amazon S3 when using EMRFS. The protocol improves application performance by avoiding rename operations in Amazon S3 during the Spark dynamic partition overwrite job commit phase.
FileCommitProtocol defines how a single Spark job commits its output. Call sequence order is basically:
- Driver calls setupJob
- As part of each task's execution, the executor calls setupTask and then commitTask (or abortTask if a task fails).
- When all tasks are completed successfully, the driver calls commitJob (or abortJob if too many task fails).
Requirements
- Spark job uses Spark SQL, DataFrames, or Dataset to write files.
- Spark jobs with
partitionOverwriteModeset asdynamic. - Multipart uploads are enabled for EMR. -- default
- The filesystem cache for EMRFS is enabled i.e
fs.s3.impl.disabled.cacheis set tofalse. --default - Spark jobs write to the default partition location.
Spark must have configs:
spark.sql.sources.commitProtocolClassmust be set toorg.apache.spark.sql.execution.datasources.SQLEmrOptimizedCommitProtocol.- The
partitionOverwriteModewrite option orspark.sql.sources.partitionOverwriteModemust be set todynamic. - While writing in an S3-location
modemust be set tooverwriteor, while inserting data into the table,overwritemust be set toTrue - If Spark jobs overwrite the Hive metastore Parquet table,
spark.sql.hive.convertMetastoreParquet,spark.sql.hive.convertInsertingPartitionedTable, andspark.sql.hive.convertMetastore.partitionOverwriteModemust be set totrue.
How does Dynamic Partition Overwrite work when enabled?
Based on Spark 3.x documentation that can be seen here :
@param dynamicPartitionOverwrite If true, Spark will overwrite partition directories at runtime
* dynamically. Suppose final path is /path/to/outputPath, output
* path of [[FileOutputCommitter]] is an intermediate path, e.g.
* /path/to/outputPath/.spark-staging-{jobId}, which is a staging
* directory. Task attempts firstly write files under the
* intermediate path, e.g.
* /path/to/outputPath/.spark-staging-{jobId}/_temporary/
* {appAttemptId}/_temporary/{taskAttemptId}/a=1/b=1/xxx.parquet.
*
* 1. When [[FileOutputCommitter]] algorithm version set to 1,
* we firstly move task attempt output files to
* /path/to/outputPath/.spark-staging-{jobId}/_temporary/
* {appAttemptId}/{taskId}/a=1/b=1,
* then move them to
* /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1.
*
* 2. When [[FileOutputCommitter]] algorithm version set to 2,
* committing tasks directly move task attempt output files to
* /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1.
*
* At the end of committing job, we move output files from
* intermediate path to final path, e.g., move files from
* /path/to/outputPath/.spark-staging-{jobId}/a=1/b=1
* to /path/to/outputPath/a=1/b=1dynamicPartitionOverwrite internal working from Spark Documentation
dynamicPartitionOverwriteflag istruewhen in spark configurationpartitionOverwriteModeis set asdynamicandfalsewhen it's set asstatici.e. default configuration.
To see how SQLEmrOptimizedCommitProtocol improves the performance, let's see what happens under the hood when SQLHadoopMapReduceCommitProtocol is used with partitionOverwriteMode as dynamic and write mode as overwrite.
Using SQLHadoopMapReduceCommitProtocol with partitionOverwriteMode set to dynamic on a partitioned Hive table
%%configure
{
"conf": {
"spark.sql.sources.commitProtocolClass":"org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol",
"spark.sql.sources.partitionOverwriteMode": "dynamic"
}
}Configuration when S3 Optimized Commit Protocol isn't used
print(
spark.conf.get("spark.sql.sources.commitProtocolClass"),
spark.conf.get("spark.sql.sources.partitionOverwriteMode"),
spark.conf.get("spark.sql.parquet.fs.optimized.committer.optimization-enabled")
spark.conf.get("spark.sql.parquet.output.committer.class"),
spark.conf.get("spark.sql.hive.convertMetastoreParquet")
)Printing all the required configurations
('org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol', 'dynamic', 'true', 'com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter','true')Output of configurations
Alright as we can see other configurations are present by default so nothing specific to be set for this. Let's create a partitioned table on which we will be writing our data.
-- can run this directly via Athena or using spark.sql
CREATE EXTERNAL TABLE `blogs_db.emr_committer_test`(
`id` int
)
PARTITIONED BY (
`dt` date
)
STORED AS PARQUET
LOCATION
's3://aws-blog-post-bucket/blogs_db/emr_committer_test'CREATE Statement for a partitioned table
from pyspark.sql.functions import date_sub,col, lit
from datetime import datetime
dataset = spark.range(0,500).withColumn("id", col("id").cast("int")).withColumn("dt", date_sub(lit(datetime.date(datetime.now())), lit(1)))
dataset.show(5)Creating a dataset that needs to be inserted into a partitioned table
+---+----------+
| id| dt|
+---+----------+
| 0|2024-02-04|
| 1|2024-02-04|
| 2|2024-02-04|
| 3|2024-02-04|
| 4|2024-02-04|
| 5|2024-02-04|
+---+----------+dataset output
# writing a single file to understand the logs easily.
spark.conf.set("hive.exec.dynamic.partition.mode","nonstrict")
dataset.coalesce(1).write.insertInto("blogs_db.emr_committer_test", overwrite=True)Writing data into the output table
Alright, let's look into the logs for this to see exactly how it's writing data.
.....
24/02/05 19:30:54 INFO SQLConfCommitterProvider: Getting user defined output committer class com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter
24/02/05 19:30:54 INFO ClientConfigurationFactory: Set initial getObject socket timeout to 2000 ms.
24/02/05 19:30:54 INFO EmrOptimizedParquetOutputCommitter: EMR Optimized Committer: ENABLED
24/02/05 19:30:54 INFO EmrOptimizedParquetOutputCommitter: Using output committer class org.apache.hadoop.mapreduce.lib.output.FileSystemOptimizedCommitter
24/02/05 19:30:54 INFO FileOutputCommitter: File Output Committer Algorithm version is 2
24/02/05 19:30:54 INFO FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: true
......
24/02/05 19:30:54 INFO FileSystemOptimizedCommitter: Created staging directory at s3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa named 0_attempt_202402051930535732531040944174447_0001_m_000000_1 when getting work path
24/02/05 19:30:54 INFO StagingUploadPlanner: Creating a new staged file 's3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/.emrfs_staging_0_attempt_202402051930535732531040944174447_0001_m_000000_1/dt=2024-02-04/part-00000-fda31ca9-c6cd-4a5b-975f-53404934c6fa.c000.snappy.parquet' with destination key 'blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/dt=2024-02-04/part-00000-fda31ca9-c6cd-4a5b-975f-53404934c6fa.c000.snappy.parquet'
24/02/05 19:30:54 INFO CodecPool: Got brand-new compressor [.snappy]
24/02/05 19:30:55 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/dt=2024-02-04/part-00000-fda31ca9-c6cd-4a5b-975f-53404934c6fa.c000.snappy.parquet
24/02/05 19:30:56 INFO MultipartUploadOutputStream: uploadPart: partNum 1 of 's3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/dt=2024-02-04/part-00000-fda31ca9-c6cd-4a5b-975f-53404934c6fa.c000.snappy.parquet' from local file '/mnt/s3/emrfs-6613074794378474867/0000000000', 2458 bytes in 34 ms, md5: 5o1rVnC1QcmjmDgJCNpNsA== md5hex: e68d6b5670b541c9a398380908da4db0
24/02/05 19:30:56 INFO FileSystemOptimizedCommitter: Publishing staging directory at s3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa named 0_attempt_202402051930535732531040944174447_0001_m_000000_1
24/02/05 19:30:56 INFO DefaultMultipartUploadDispatcher: Completed multipart upload of 1 parts 2458 bytes
24/02/05 19:30:56 INFO InMemoryStagingDirectory: Completed deferred upload of 's3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/dt=2024-02-04/part-00000-fda31ca9-c6cd-4a5b-975f-53404934c6fa.c000.snappy.parquet' under staging directory at 's3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/.emrfs_staging_0_attempt_202402051930535732531040944174447_0001_m_000000_1'
24/02/05 19:30:56 INFO DeferredUploadStatistics: Completed 1 deferred upload(s) under staging directory at 's3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/.emrfs_staging_0_attempt_202402051930535732531040944174447_0001_m_000000_1' (upload completion deferral time (msec): min=113, avg=113, median=113, max=113; file size (bytes): min=2458, avg=2458, median=2458, max=2458)
24/02/05 19:30:56 INFO FileSystemOptimizedCommitter: Deleting staging directory at s3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa named 0_attempt_202402051930535732531040944174447_0001_m_000000_1
24/02/05 19:30:56 INFO SparkHadoopMapRedUtil: attempt_202402051930535732531040944174447_0001_m_000000_1: Committed. Elapsed time: 93 ms.
24/02/05 19:30:56 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 3064 bytes result sent to driver
.....
24/02/05 19:30:56 INFO FileFormatWriter: Start to commit write Job c4e259c8-48c9-48a2-996f-4a3c0c2b4dc5.
24/02/05 19:30:56 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/_SUCCESS
24/02/05 19:30:56 INFO S3NativeFileSystem: rename s3://aws-blog-post-bucket/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/dt=2024-02-04 s3://aws-blog-post-bucket/blogs_db/emr_committer_test/dt=2024-02-04 using algorithm version 1
24/02/05 19:30:57 INFO FileFormatWriter: Write Job c4e259c8-48c9-48a2-996f-4a3c0c2b4dc5 committed. Elapsed time: 694 ms.
24/02/05 19:30:57 INFO FileFormatWriter: Finished processing stats for write job c4e259c8-48c9-48a2-996f-4a3c0c2b4dc5.
.....INFO Logs of the application
Here's a quick overview of what is exactly happening in the different phases of the write process.
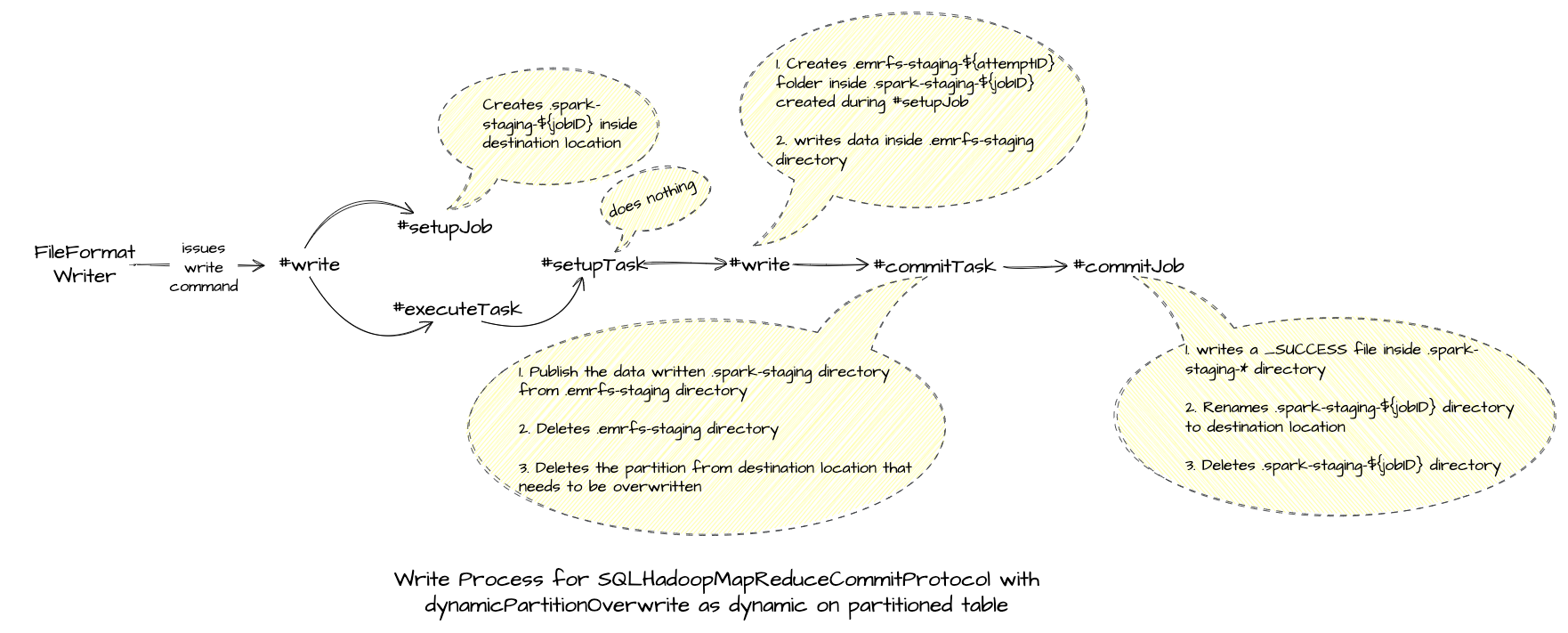
Now if we look into logs, will observe the following things:
.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fadirectory is created within the output/destination location i.e.s3://aws-blog-post-bucket/blogs_db/emr_committer_test- Inside this
.spark-staging-${jobId}directory another staging directory is created for writing the data i.e..emrfs_staging_0_attempt_202402051930535732531040944174447_0001_m_000000_1which is an attempt directory. - Data is first written into an EMR Local location
/mnt/s3/emrfs-6613074794378474867/and then from there, it's uploaded to.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fadirectory. - A success file
_SUCCESSis written into.spark-staging-${jobId}directory, which mentions that the task write is completed successfully. - Finally, a rename happens for
.spark-staging-${jobId}directory to the final destination directory i.e.s3://aws-blog-post-bucket/blogs_db/emr_committer_test/dt=2024-02-04using algorithm version 1 which means a sequential rename. - This rename can be super expensive based on the number of files that need to be renamed and the file size as we mentioned earlier in the issues with the rename in Object Storages.
- OutputCommitter used is
FileSystemOptimizedCommitter.
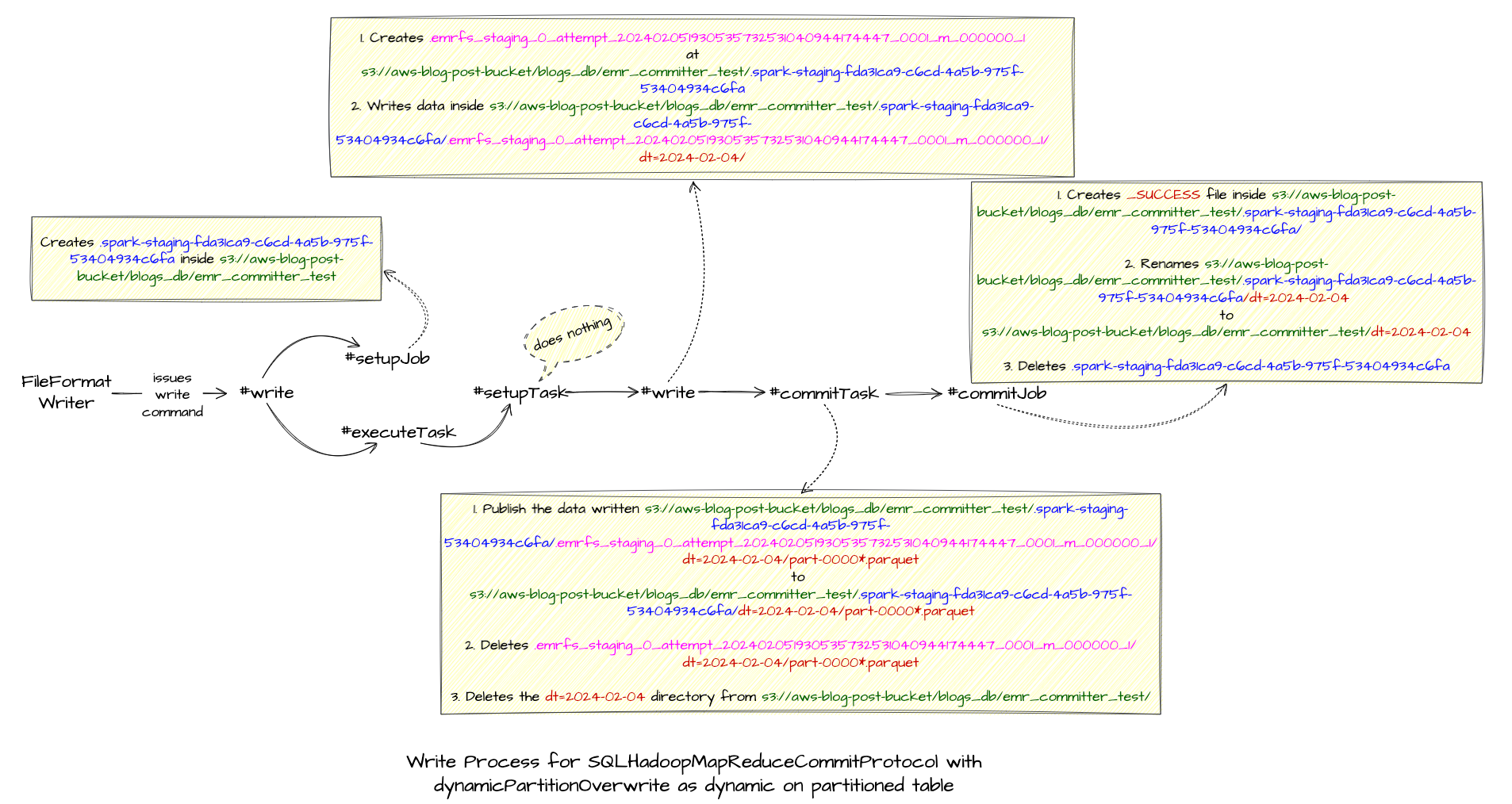
As it involves renaming of file and data is not directly written into destination directly, it can be seen that the writes are expensive hence your spark job will take more time to perform writes.
Let's look into what happens when we use SQLEmrOptimizedCommitProtocol for partitionOverwriteMode as dynamic
Using SQLEmrOptimizedCommitProtocol with dynamicOverwrite set to dynamic on a partitioned Hive table
%%configure
{
"conf": {
"spark.sql.sources.commitProtocolClass":"org.apache.spark.sql.execution.datasources.SQLEmrOptimizedCommitProtocol",
"spark.sql.sources.partitionOverwriteMode": "dynamic"
}
}Setting the configuration to use SQLEmrOptimizedCommitProtocol
print(
spark.conf.get("spark.sql.sources.commitProtocolClass"),
spark.conf.get("spark.sql.sources.partitionOverwriteMode"),
spark.conf.get("spark.sql.parquet.fs.optimized.committer.optimization-enabled")
spark.conf.get("spark.sql.parquet.output.committer.class"),
spark.conf.get("spark.sql.hive.convertMetastoreParquet")
)Printing required configurations
('org.apache.spark.sql.execution.datasources.SQLEmrOptimizedCommitProtocol', 'dynamic', 'true', 'com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter','true')Configurations output
from pyspark.sql.functions import date_sub,col, lit
from datetime import datetime
dataset = spark.range(0,500).withColumn("id", col("id").cast("int")).withColumn("dt", lit(datetime.date(datetime.now())))
dataset.show(5)Creating dataset
+---+----------+
| id| dt|
+---+----------+
| 0|2024-02-05|
| 1|2024-02-05|
| 2|2024-02-05|
| 3|2024-02-05|
| 4|2024-02-05|
| 5|2024-02-05|
+---+----------+Dataset Output
# writing a single file to understand the logs easily.
spark.conf.set("hive.exec.dynamic.partition.mode","nonstrict")
dataset.coalesce(1).write.insertInto("blogs_db.emr_committer_test", overwrite=True)Writing data into a partitioned table
Let's take a look at the logs to see the differences compared to the previous case
24/02/05 19:23:00 INFO FileSystemOptimizedCommitter: Nothing to setup as successful task attempt outputs are written directly
.....
24/02/05 19:23:07 INFO SQLConfCommitterProvider: Getting user defined output committer class com.amazon.emr.committer.EmrOptimizedSparkSqlParquetOutputCommitter
24/02/05 19:23:07 INFO EmrOptimizedParquetOutputCommitter: EMR Optimized Committer: ENABLED
24/02/05 19:23:07 INFO EmrOptimizedParquetOutputCommitter: Using output committer class org.apache.hadoop.mapreduce.lib.output.FileSystemOptimizedCommitter
24/02/05 19:23:07 INFO FileOutputCommitter: File Output Committer Algorithm version is 2
24/02/05 19:23:07 INFO FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: true
.....
24/02/05 19:23:08 INFO StagingUploadPlanner: Creating a new staged file 's3://aws-blog-post-bucket/blogs_db/emr_committer_test/dt=2024-02-05/.emrfs_staging_9f31fb50-1a77-47dd-8cf5-779e36a61b12-0-1/part-00000-9f31fb50-1a77-47dd-8cf5-779e36a61b12.c000.snappy.parquet' with destination key 'blogs_db/emr_committer_test/dt=2024-02-05/part-00000-9f31fb50-1a77-47dd-8cf5-779e36a61b12.c000.snappy.parquet'
24/02/05 19:23:08 INFO CodecPool: Got brand-new compressor [.snappy]
24/02/05 19:23:09 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test/dt=2024-02-05/part-00000-9f31fb50-1a77-47dd-8cf5-779e36a61b12.c000.snappy.parquet
24/02/05 19:23:10 INFO MultipartUploadOutputStream: uploadPart: partNum 1 of 's3://aws-blog-post-bucket/blogs_db/emr_committer_test/dt=2024-02-05/part-00000-9f31fb50-1a77-47dd-8cf5-779e36a61b12.c000.snappy.parquet' from local file '/mnt/s3/emrfs-4722872899796052640/0000000000', 2458 bytes in 36 ms, md5: oDnjr2ghLg12wB9dyZPJMg== md5hex: a039e3af68212e0d76c01f5dc993c932
24/02/05 19:23:10 INFO SparkHadoopMapRedUtil: No need to commit output of task because needsTaskCommit=false: attempt_20240205192300177985718977635494_0001_m_000000_1
24/02/05 19:23:10 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 4072 bytes result sent to driver
24/02/05 19:23:10 INFO FileFormatWriter: Start to commit write Job 7fe83e0a-bc20-44ac-a6c2-bae513934abc.
24/02/05 19:23:10 INFO MultipartUploadOutputStream: close closed:false s3://aws-blog-post-bucket/blogs_db/emr_committer_test/_SUCCESS
24/02/05 19:23:10 INFO FileFormatWriter: Write Job 7fe83e0a-bc20-44ac-a6c2-bae513934abc committed. Elapsed time: 469 ms.
24/02/05 19:23:10 INFO FileFormatWriter: Finished processing stats for write job 7fe83e0a-bc20-44ac-a6c2-bae513934abc.
.....The main differences are:
- There is no creation of any
.spark-staging-${jobId}path within the target table location, only an.emrfs_staging_${jobId}is created. - There is NO renaming of files happening as the data is being directly multipart uploaded into the target table location.
- No Task Ouput Commit happens as the data is directly written into target table location.
- A
_SUCCESSfile is written directly into the table location while the job is being committed. - OutputCommiter used is
FileSystemOptimizedCommitter
Now if you are wondering
Why there is such a difference in both the cases when the OutputCommitter used in both the cases is same i.e. FileSystemOptimizedCommitter ?
The reason for this is the committer protocol class that is being used in both the cases. Both SQLEmrOptimizedCommitProtocol and SQLHadoopMapReduceCommitProtocol (that extends HadoopMapReduceCommitProtocol ) are an alternative implementation of FileCommitProtocol), but in both the cases how different stages (like setupTask, commitTask, commitJob etc.) are handled is quite different and hence the difference in both the cases.
One of the things that we can't see in the INFO logs, is deletion of the already existing data files when overwrite mode is being provided as true.
How listing operations are avoided?
Listing operations are mainly used while checking whether the output location is already exists and in case of overwrite = True, it's used to identify if there are any files already existing in the location so as to issue a DELETE for removing those files first before committing the Task outputs.
To avoid any listing operations from the destination location i.e. table S3 location, the multiple HTTPS requests are sent to S3 URI. All these requests being made can be seen in the DEBUG logs for the job. There are mainly 4 requests that are made:
- HEAD requests to check if a S3 location is existing or not.
- GET requests to check if there are any files (i.e. keys in AWS S3 terms) present in an S3 output location.
- DELETE requests for deleting the staging keys/folders (like
.spark_staging_${jobID}), files/keys present in the destination location in case of overwrite mode is given (i.e. in case of S3 writesmode("overwrite"), in case of table writes.insertInto("table-name", overwrite=True). - PUT requests are made to create
_SUCCESSfile in case the taskCommit or jobCommit is successful.
Let's look at a few of these requests made from the debug logs, to run your spark jobs in DEBUG mode
spark.sparkContext.setLogLevel("DEBUG")Setting Log level as DEBUG
....
24/02/05 19:30:53 DEBUG request: Sending Request: HEAD https://aws-blog-post-bucket.s3.ap-south-1.amazonaws.com /blogs_db/emr_committer_test
24/02/05 19:30:53 DEBUG AWS4Signer: AWS4 Canonical Request: '"HEAD
/blogs_db/emr_committer_test
amz-sdk-invocation-id:bf3124d6-6b90-a9e9-bb76-21a48a80da25
amz-sdk-request:ttl=20240205T193143Z;attempt=1;max=16
amz-sdk-retry:0/0/500
content-type:application/octet-stream
host:aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
....
24/02/05 19:30:53 DEBUG headers: http-outgoing-0 >> HEAD /blogs_db/emr_committer_test HTTP/1.1
24/02/05 19:30:53 DEBUG headers: http-outgoing-0 >> Host: aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
24/02/05 19:30:53 DEBUG headers: http-outgoing-0 >> amz-sdk-invocation-id: bf3124d6-6b90-a9e9-bb76-21a48a80da25
24/02/05 19:30:53 DEBUG headers: http-outgoing-0 >> amz-sdk-request: ttl=20240205T193143Z;attempt=1;max=16
24/02/05 19:30:53 DEBUG headers: http-outgoing-0 >> amz-sdk-retry: 0/0/500
....
24/02/05 19:30:53 DEBUG wire: http-outgoing-0 << "HTTP/1.1 404 Not Found[\r][\n]"
24/02/05 19:30:53 DEBUG wire: http-outgoing-0 << "x-amz-request-id: 26J4H9CB6BEYRC1E[\r][\n]"
24/02/05 19:30:53 DEBUG wire: http-outgoing-0 << "x-amz-id-2: uZg2W6jHCmpyOn9dVkVxQhMNackVGxkj5R2z1RplpjdixjVT032h0lQTHf8o81oE6udYN+3J3co=[\r][\n]"
24/02/05 19:30:53 DEBUG wire: http-outgoing-0 << "Content-Type: application/xml[\r][\n]"
24/02/05 19:30:53 DEBUG wire: http-outgoing-0 << "Date: Mon, 05 Feb 2024 19:30:52 GMT[\r][\n]"
24/02/05 19:30:53 DEBUG wire: http-outgoing-0 << "Server: AmazonS3[\r][\n]"
24/02/05 19:30:53 DEBUG wire: http-outgoing-0 << "[\r][\n]"
....HEAD Request for checking /blogs_db/emr_committer_test exists or not
....
24/02/05 19:30:57 DEBUG request: Sending Request: GET https://aws-blog-post-bucket.s3.ap-south-1.amazonaws.com /
24/02/05 19:30:57 DEBUG AWS4Signer: AWS4 Canonical Request: '"GET
/
fetch-owner=false&list-type=2&max-keys=1000&prefix=blogs_db%2Femr_committer_test%2F.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa%2F
amz-sdk-invocation-id:0a4db3c4-2c58-02bf-59a9-cad35fc32de6
amz-sdk-request:ttl=20240205T193147Z;attempt=1;max=16
amz-sdk-retry:0/0/500
content-type:application/octet-stream
host:aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
....
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> GET /?list-type=2&max-keys=1000&prefix=blogs_db%2Femr_committer_test%2F.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa%2F&fetch-owner=false HTTP/1.1
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> Host: aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> amz-sdk-invocation-id: 0a4db3c4-2c58-02bf-59a9-cad35fc32de6
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> amz-sdk-request: ttl=20240205T193147Z;attempt=1;max=16
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> amz-sdk-retry: 0/0/500
....
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "HTTP/1.1 200 OK[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "x-amz-id-2: XFZ/jh1Xkt11NVF1O06k1SiIpDZ+U4HwjzAMRsEpVFIt/q2miRgtjPOi8kft8cpHnfCJr9Auo5c=[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "x-amz-request-id: MF5EV02PNJ8N2Z4R[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "Date: Mon, 05 Feb 2024 19:30:58 GMT[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "x-amz-bucket-region: ap-south-1[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "Content-Type: application/xml[\r][\n]"
....
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "264[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "<?xml version="1.0" encoding="UTF-8"?>[\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "<ListBucketResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Name>aws-blog-post-bucket</Name><Prefix>blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/</Prefix><KeyCount>1</KeyCount><MaxKeys>1000</MaxKeys><IsTruncated>false</IsTruncated><Contents><Key>blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/_SUCCESS</Key><LastModified>2024-02-05T19:30:57.000Z</LastModified><ETag>"d41d8cd98f00b204e9800998ecf8427e"</ETag><Size>0</Size><StorageClass>STANDARD</StorageClass></Contents></ListBucketResult>[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "0[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "[\r][\n]"
....GET Request for checking if there are keys present within .spark-staging-${jobId}
....
24/02/05 19:30:57 DEBUG request: Sending Request: DELETE https://aws-blog-post-bucket.s3.ap-south-1.amazonaws.com /blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/
24/02/05 19:30:57 DEBUG AWS4Signer: AWS4 Canonical Request: '"DELETE
/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/
amz-sdk-invocation-id:dcd1e575-6600-cf26-469f-fef11ee99b44
amz-sdk-request:ttl=20240205T193147Z;attempt=1;max=16
amz-sdk-retry:0/0/500
content-type:application/octet-stream
host:aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
....
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> DELETE /blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/ HTTP/1.1
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> Host: aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> amz-sdk-invocation-id: dcd1e575-6600-cf26-469f-fef11ee99b44
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> amz-sdk-request: ttl=20240205T193147Z;attempt=1;max=16
24/02/05 19:30:57 DEBUG headers: http-outgoing-0 >> amz-sdk-retry: 0/0/500
....
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 >> "DELETE /blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/ HTTP/1.1[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 >> "Host: aws-blog-post-bucket.s3.ap-south-1.amazonaws.com[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 >> "amz-sdk-invocation-id: dcd1e575-6600-cf26-469f-fef11ee99b44[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 >> "amz-sdk-request: ttl=20240205T193147Z;attempt=1;max=16[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 >> "amz-sdk-retry: 0/0/500[\r][\n]"
....
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "HTTP/1.1 204 No Content[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "x-amz-id-2: jnCDkrNScjYRupyqwaCIuAKnr147V0V4/hT+JTwYySUwH525dqlB260uEPeeSBwJZnUitR3Ut6Q=[\r][\n]"
24/02/05 19:30:57 DEBUG wire: http-outgoing-0 << "x-amz-request-id: MF5B44HC8BK252Q4[\r][\n]"
....DELETE Request for deleting .spark-staging-${jobID}
....
24/02/05 19:30:56 DEBUG request: Sending Request: PUT https://aws-blog-post-bucket.s3.ap-south-1.amazonaws.com /blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/_SUCCESS
24/02/05 19:30:56 DEBUG AWS4Signer: AWS4 Canonical Request: '"PUT
/blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/_SUCCESS
amz-sdk-invocation-id:726a9855-aeae-0780-2507-be932928a8b7
amz-sdk-request:attempt=1;max=16
amz-sdk-retry:0/0/500
content-length:0
content-md5:1B2M2Y8AsgTpgAmY7PhCfg==
content-type:binary/octet-stream
host:aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
....
24/02/05 19:30:56 DEBUG headers: http-outgoing-0 >> PUT /blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/_SUCCESS HTTP/1.1
24/02/05 19:30:56 DEBUG headers: http-outgoing-0 >> Host: aws-blog-post-bucket.s3.ap-south-1.amazonaws.com
24/02/05 19:30:56 DEBUG headers: http-outgoing-0 >> amz-sdk-invocation-id: 726a9855-aeae-0780-2507-be932928a8b7
24/02/05 19:30:56 DEBUG headers: http-outgoing-0 >> amz-sdk-request: attempt=1;max=16
24/02/05 19:30:56 DEBUG headers: http-outgoing-0 >> amz-sdk-retry: 0/0/500
....
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 >> "PUT /blogs_db/emr_committer_test/.spark-staging-fda31ca9-c6cd-4a5b-975f-53404934c6fa/_SUCCESS HTTP/1.1[\r][\n]"
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 >> "Host: aws-blog-post-bucket.s3.ap-south-1.amazonaws.com[\r][\n]"
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 >> "amz-sdk-invocation-id: 726a9855-aeae-0780-2507-be932928a8b7[\r][\n]"
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 >> "amz-sdk-request: attempt=1;max=16[\r][\n]"
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 >> "amz-sdk-retry: 0/0/500[\r][\n]"
....
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 << "HTTP/1.1 200 OK[\r][\n]"
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 << "x-amz-id-2: mVMMYJNuElx/NLPZlSZ2YXpf8s+dDWAp1EV37cQo5q7iaEs46LbI/oQUQ3P1y2h2yCGNmlXqcrg=[\r][\n]"
24/02/05 19:30:56 DEBUG wire: http-outgoing-0 << "x-amz-request-id: MVMQSK7TEF0YAFKE[\r][\n]"
....PUT request for creating _SUCCESS file inside .spark-staging-${jobID} on taskCommit
Summarization
We looked into how EMRFS S3-Optimized Committer and Commit Protocol improves the write performance by avoiding the rename operation during task and job commits. Also, to develop a deeper understanding of these, we looked into logs to analyze what happens under the hood when the writes are being optimized and when not.
Here's a table for quick reference:

We also looked into how listing operations are done using HTTPS calls to the S3 URI in the backend for various scenarios.
I hope you know now how to look into your job logs and identify whether EMRFS S3-Optimized committer and committer protocols are working for your Spark Job. I would highly suggest looking into the documentation once for the cases where both of these doesn't work and some considerations while using multipart uploads.
As for the performance improvement over FileOutputCommitter V2, it improves the write performance by 1.6x
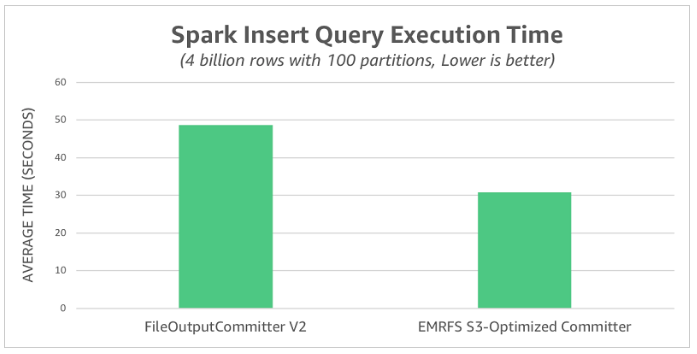
You can check the entire blog post here that details the performance improvement for EMRFS S3-Optimized Committer.

That's it for this one folks.!! 😊 See you in next one. 🚀
If it has added any value to you and want to read more content like this, subscribe to the newsletter, it's free of cost and I will make sure every post is worth your time and makes you a better Data Engineer.



Member discussion