PyDeequ - Testing Data Quality at Scale

This blog post will cover the different components of PyDeequ and how to use PyDeequ to test data quality in depth.
What is PyDeequ?
PyDeequ is an open-source Python wrapper around Deequ (an open-source tool developed and used in Amazon). Deequ allows you to calculate data quality metrics on your dataset, define and verify data quality constraints, and be informed about changes in the data distribution. It's built on top of Apache Spark so it can scale with large datasets (billions of rows).
Why testing Data Quality is important?
The quality of data within a system can make or break your application. Incorrect, missing, or malformed data can have a large impact on production systems. This bad data quality in the system can result in failures in Production, unexpected output from ML models, wrong business decisions, and much more.
Environment and Data Preparation:
You can run this on your local machine too, if you have an Apache Spark setup in your workstation. I will be using EMR 6.11 that comes with Spark 3.3
The data that I am using for this is NYC Yellow Taxi Trip record data. It can be accessed here along with the Data Dictionary if you are interested in understanding the data a bit.
Installing Pydeequ in EMR
sudo python3 -m pip install pydeequInstalling pydeequ Python Package
Setting up SparkSession Configuration in Notebook:
Before you can import pydeequ, we need to set SPARK_VERSION in environment variables as pydeequ tries to get it from environment variables.
import os
os.environ['SPARK_VERSION'] = '3.3'Setting SPARK_VERSION in Environment Variables
import pydeequImporting PyDeequ
print(pydeequ.deequ_maven_coord, pydeequ.f2j_maven_coord)Getting values for including jars for deequ
%%configure -f
{
"conf": {
"spark.jars.packages": "com.amazon.deequ:deequ:2.0.3-spark-3.3",
"spark.jars.excludes": "net.sourceforge.f2j:arpack_combined_all"
}
}Configuring Spark Session in EMR Notebook
Reading data from S3:
bucket_name = "your-s3-bucket"
yellow_df = spark.read.parquet(f"s3://{bucket_name}/raw/tlc_data/yellow/oct2023/")
yellow_df.printSchema()Reading TLC data from S3 and checking schema
root
|-- VendorID: integer (nullable = true)
|-- tpep_pickup_datetime: timestamp (nullable = true)
|-- tpep_dropoff_datetime: timestamp (nullable = true)
|-- passenger_count: long (nullable = true)
|-- trip_distance: double (nullable = true)
|-- RatecodeID: long (nullable = true)
|-- store_and_fwd_flag: string (nullable = true)
|-- PULocationID: integer (nullable = true)
|-- DOLocationID: integer (nullable = true)
|-- payment_type: long (nullable = true)
|-- fare_amount: double (nullable = true)
|-- extra: double (nullable = true)
|-- mta_tax: double (nullable = true)
|-- tip_amount: double (nullable = true)
|-- tolls_amount: double (nullable = true)
|-- improvement_surcharge: double (nullable = true)
|-- total_amount: double (nullable = true)
|-- congestion_surcharge: double (nullable = true)
|-- Airport_fee: double (nullable = true)TLC Data Schema
PyDeequ components:
Let's look into the various components of PyDeequ via code examples to make more sense of which component can be used and when.
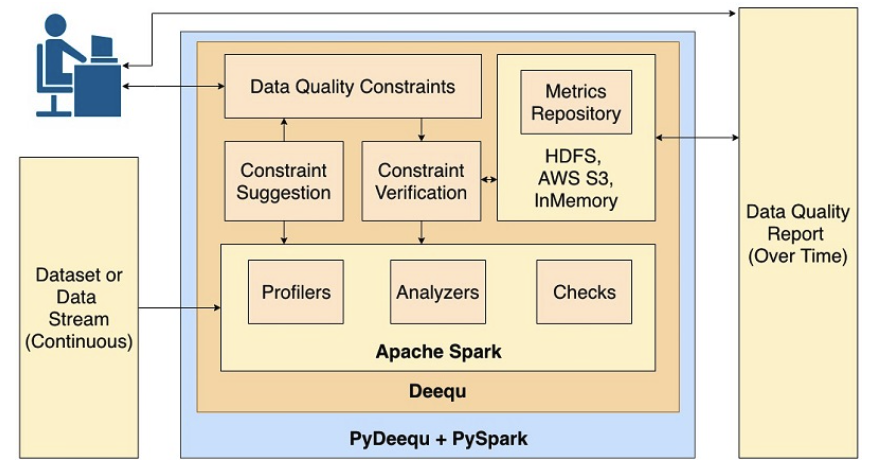
Metrics Computation
- Deequ computes data quality metrics, that is, statistics such as completeness, maximum, or correlation.
- This can mainly be used for Data Analysis. Deequ provides Profilers and Analyzers to do that.
Profilers
Let's say you don't know much about the data like what is the completeness level of columns, which column has nulls, non-negative values, uniqueness, distinctness, etc.
In this case, we can just run a profiler on the entire data and Deequ will provide us with all the stats for these.
# Profiling Data
from pydeequ.profiles import ColumnProfilerRunner
# Profiling all the columns: ColumnProfilerRunner.onData returns a ColumnProfilerRunBuilder
result = ColumnProfilerRunner(spark) \
.onData(yellow_df) \
.run()
# printing all the columns and their corresponding profiled data.
for col_name, profile in result.profiles.items():
print(col_name)
print(profile)Running a PyDeequ's ColumnProfiler on data
...
tpep_dropoff_datetime
StandardProfiles for column: tpep_dropoff_datetime: {
"completeness": 1.0,
"approximateNumDistinctValues": 1723476,
"dataType": "String",
"isDataTypeInferred": false,
"typeCounts": {},
"histogram": null
}
PULocationID
NumericProfiles for column: PULocationID: {
"completeness": 1.0,
"approximateNumDistinctValues": 259,
"dataType": "Integral",
"isDataTypeInferred": false,
"typeCounts": {},
"histogram": null,
"kll": "None",
"mean": 165.42121719281658,
"maximum": 265.0,
"minimum": 1.0,
"sum": 582660672.0,
"stdDev": 64.06097676325575,
"approxPercentiles": []
}
trip_distance
NumericProfiles for column: trip_distance: {
"completeness": 1.0,
"approximateNumDistinctValues": 4888,
"dataType": "Fractional",
"isDataTypeInferred": false,
"typeCounts": {},
"histogram": null,
"kll": "None",
"mean": 3.926694986351057,
"maximum": 205544.17,
"minimum": 0.0,
"sum": 13830938.849999534,
"stdDev": 196.60951653021021,
"approxPercentiles": []
}
....
Sample Profiler Output
In case, you are just interested in a few columns in the data, let's say VendorID, trip_distance and total_amount are the columns of interest. In this case, ColumnProfiler can be restricted only to these methods.
from pydeequ.profiles import ColumnProfilerRunner
# Restricting to columns of interest only
column_profiler = ColumnProfilerRunner(spark) \
.onData(yellow_df) \
.restrictToColumns(['VendorID', 'trip_distance', 'total_amount'])\
.run()
for col_name, profile in column_profiler.profiles.items():
print(col_name)
print(profile)ColumnProfiler with restricted columns
VendorID
NumericProfiles for column: VendorID: {
"completeness": 1.0,
"approximateNumDistinctValues": 3,
"dataType": "Integral",
"isDataTypeInferred": false,
"typeCounts": {},
"histogram": [
[
"2",
2617320,
0.7430744530894008
],
[
"1",
904463,
0.25678302579149614
],
[
"6",
502,
0.00014252111910308224
]
],
"kll": "None",
"mean": 1.7437870586849162,
"maximum": 6.0,
"minimum": 1.0,
"sum": 6142115.0,
"stdDev": 0.4397934656174618,
"approxPercentiles": []
}
trip_distance
NumericProfiles for column: trip_distance: {
"completeness": 1.0,
"approximateNumDistinctValues": 4888,
"dataType": "Fractional",
"isDataTypeInferred": false,
"typeCounts": {},
"histogram": null,
"kll": "None",
"mean": 3.926694986351057,
"maximum": 205544.17,
"minimum": 0.0,
"sum": 13830938.849999534,
"stdDev": 196.60951653021021,
"approxPercentiles": []
}
total_amount
NumericProfiles for column: total_amount: {
"completeness": 1.0,
"approximateNumDistinctValues": 17649,
"dataType": "Fractional",
"isDataTypeInferred": false,
"typeCounts": {},
"histogram": null,
"kll": "None",
"mean": 29.17137076076931,
"maximum": 6339.0,
"minimum": -901.0,
"sum": 102749881.66009633,
"stdDev": 24.315046732781724,
"approxPercentiles": []
}Profiler output on specific columns
Based on the profiler output, you can effectively decide what all columns are interest to you and if that column actually needs some cleansing or transformations.
Analyzers
Analyzers can be used to get some specific metrics on columns of interest. PyDeequ supports a rich set of metrics. AnalysisRunner can be used to capture the metrics we are interested in.
from pydeequ.analyzers import AnalysisRunner, AnalyzerContext, Size, Completeness, Distinctness, Uniqueness, Compliance, Mean, Sum, Maximum
# Adding Analyzers for metrics computation
analysisResult = AnalysisRunner(spark) \
.onData(yellow_df) \
.addAnalyzer(Size()) \
.addAnalyzer(Completeness("VendorID")) \
.addAnalyzer(Distinctness("VendorID")) \
.addAnalyzer(Uniqueness(["VendorID", "payment_type"])) \
.addAnalyzer(Compliance("payment_type", "payment_type in (1,2,3,4,5,6)")) \
.addAnalyzer(Mean("trip_distance")) \
.addAnalyzer(Sum("total_amount")) \
.addAnalyzer(Maximum("extra")) \
.run()
analysisResult_df = AnalyzerContext.successMetricsAsDataFrame(spark, analysisResult)
analysisResult_df.show()Running Analyzers to get specific metrics on specific columns
%%display
analysisResult_df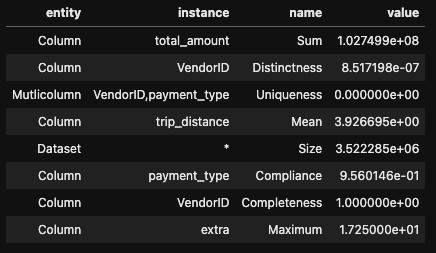
An important thing to notice here is that you can run some of the Analyzers on multiple columns too like in above exampleUniqueness(["VendorID", "payment_type"]to see the uniqueness for the combination ofVendorIDandpayment_typecolumns.
A list of all the available Analyzers in PyDeequ can be seen here.
Constraint Suggestion
You can think of constraints as the Data Quality Rules that your data should follow to be called good data.
PyDeequ can help you by suggesting the constraints that you can apply to the columns by running a profiler on the data. Also, it provides the details of how a particular constraint can be applied during the verification
from pydeequ.suggestions import ConstraintSuggestionRunner, DEFAULT
import json
suggestionResult = ConstraintSuggestionRunner(spark) \
.onData(yellow_df) \
.addConstraintRule(DEFAULT()) \
.run()
# Constraint Suggestions in JSON format
print(json.dumps(suggestionResult, indent=2))Getting Constraint Suggestions from PyDeequ
If you are interested in knowing if a particular constraint is applicable for columns are not, that can be checked by adding particular constraint rules instead of DEFAULT()
from pydeequ.suggestions import ConstraintSuggestionRunner, NonNegativeNumbersRule, RetainTypeRule, RetainCompletenessRule
import json
# Running specific suggestion rules, helps in knowing if a particular rule is suggested or not and how it can actually be implemented.
# Check Airport_fee > RetainCompletenessRule()
specific_suggestion_result = ConstraintSuggestionRunner(spark) \
.onData(yellow_df) \
.addConstraintRule(NonNegativeNumbersRule()) \
.addConstraintRule(RetainTypeRule()) \
.addConstraintRule(RetainCompletenessRule()) \
.run()
# Constraint Suggestions in JSON format
print(json.dumps(specific_suggestion_result, indent=2))Checking for NonNegativeNumberRule along with Completeness and Type Rules
{
"constraint_suggestions": [
{
"constraint_name": "ComplianceConstraint(Compliance('trip_distance' has no negative values,trip_distance >= 0,None))",
"column_name": "trip_distance",
"current_value": "Minimum: 0.0",
"description": "'trip_distance' has no negative values",
"suggesting_rule": "NonNegativeNumbersRule()",
"rule_description": "If we see only non-negative numbers in a column, we suggest a corresponding constraint",
"code_for_constraint": ".isNonNegative(\"trip_distance\")"
},
{
"constraint_name": "CompletenessConstraint(Completeness(Airport_fee,None))",
"column_name": "Airport_fee",
"current_value": "Completeness: 0.9560146325467701",
"description": "'Airport_fee' has less than 5% missing values",
"suggesting_rule": "RetainCompletenessRule()",
"rule_description": "If a column is incomplete in the sample, we model its completeness as a binomial variable, estimate a confidence interval and use this to define a lower bound for the completeness",
"code_for_constraint": ".hasCompleteness(\"Airport_fee\", lambda x: x >= 0.95, \"It should be above 0.95!\")"
},
....
}
]
}Sample Output for Constraint Suggestion on specific columns
Supported constraint suggestions can be seen here.
Constraint Verification
As a user, you focus on defining a set of data quality constraints to be verified. Deequ takes care of deriving the required set of metrics to be computed on the data. Deequ generates a data quality report, which contains the result of the constraint verification.
This is where you define the data quality test cases to verify some specific constraints on columns.
Let's add a column called gen_id in dataframe just to see how the rules around uniqueness work.
from pyspark.sql.functions import col, monotonically_increasing_id
# Adding a column gen_id to check the rules around uniqueness and column combination uniqueness in Pydeequ
sample_df = yellow_df.withColumn("gen_id", monotonically_increasing_id())Adding gen_id column to test the rules around uniqueness
Let's create some DQ constraints that can be verified by PyDeequ.
DQ Constraints for Verification are defined as Check that can further be added into VerificationSuite.
from pydeequ.checks import *
from pydeequ.verification import *
# Check represents a list of constraints that can be applied to a provided Spark Dataframe
# Defining only single check here but it can be one check per column
check = Check(spark, CheckLevel.Warning, "NYC Yellow Taxi Trips Oct 2023")
checkResult = VerificationSuite(spark) \
.onData(sample_df) \
.addCheck(
check.isComplete("VendorID") \
.isUnique("gen_id") \
.hasUniqueness(["VendorID", "gen_id"], assertion=lambda x: x==1) \
.hasCompleteness("Airport_fee", assertion=lambda x: x >= 0.95) \
.isNonNegative("fare_amount")) \
.run()
print(f"Verification Run Status: {checkResult.status}")
# Checking the results of the verification
checkResult_df = VerificationResult.checkResultsAsDataFrame(spark, checkResult)
Creating Verification checks and running them
%%display
checkResult_df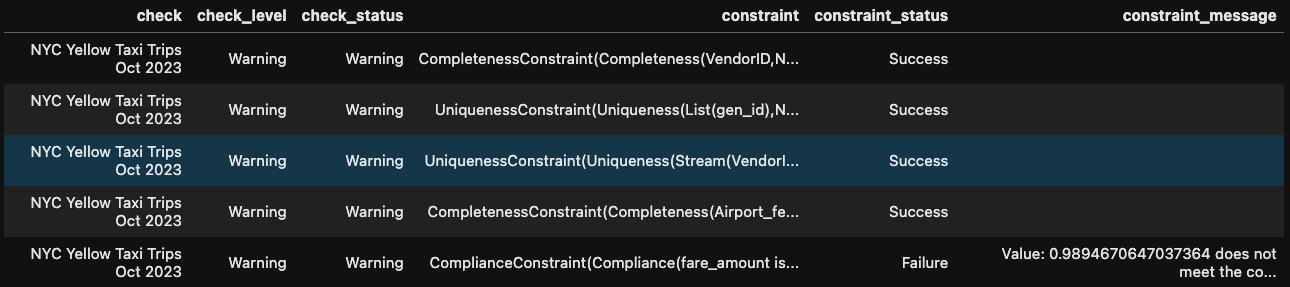
If you notice here, for Airport_fee I have applied a particular assertion mentioning that the completeness of this column should be >= 0.95 . I have got this constraint from the ConstraintSuggestion, that we ran previously. If you notice the output it's mentioned like this:
{
"constraint_name": "CompletenessConstraint(Completeness(Airport_fee,None))",
"column_name": "Airport_fee",
"current_value": "Completeness: 0.9560146325467701",
"description": "'Airport_fee' has less than 5% missing values",
"suggesting_rule": "RetainCompletenessRule()",
"rule_description": "If a column is incomplete in the sample, we model its completeness as a binomial variable, estimate a confidence interval and use this to define a lower bound for the completeness",
"code_for_constraint": ".hasCompleteness(\"Airport_fee\", lambda x: x >= 0.95, \"It should be above 0.95!\")"
}code_for_constraintkey has the code that I have used in thechecksand this is one example, of how you can use constraint suggestions during Constraint Verification
# Checking all the metrics values from Verification Results
VerificationResult.successMetricsAsDataFrame(spark, checkResult).show(truncate=False)Checking the metrics values from Verification Results
Better Ways to Define Checks for Constraint Verification
- Checks can also be separated or grouped based on the DQ logic so the verification results can make more sense.
- Instead of defining all the column checks in one
Check, it can be split into multiple checks. - For each
Check, you can define differentCheckLevel, depending upon how strict of a DQ check it is. - These are specifically useful when you want to identify easily what check has failed and you can automate a solution to fix this if required. For example, if
fare_amountchecks are failed, as per your business logic, you can filter out all the outliers and write them into a different table. - Check the example below for this.
# Rewriting checks in better way
VendorID_check = Check(spark, CheckLevel.Error, "VendorID Checks")
genid_uniq_check = Check(spark, CheckLevel.Error, "gen_id Checks")
non_ngtv_checks = Check(spark, CheckLevel.Warning, "fare_amount Checks")
non_impacting_checks = Check(spark, CheckLevel.Warning, "Common Checks")
checkResult = VerificationSuite(spark) \
.onData(sample_df) \
.addCheck(VendorID_check.isComplete("VendorID")) \
.addCheck(genid_uniq_check.isUnique("gen_id")) \
.addCheck(non_impacting_checks.hasUniqueness(["VendorID", "gen_id"], assertion=lambda x: x==1) \
.hasCompleteness("Airport_fee", assertion=lambda x: x >= 0.95)) \
.addCheck(non_ngtv_checks.isNonNegative("fare_amount")) \
.run()
# Checking the results of the verification
checkResult_df = VerificationResult.checkResultsAsDataFrame(spark, checkResult)Better ways of Defining checks so Verification Results make more sense
All the available checks in PyDeequ can be seen here.
Metrics Repositories
Now this is one of my favourite components. PyDeequ gives the ability to store and load the metrics from a repository.
We can create a repository that can be mentioned during data analysis or running constraint verifications. The data stored in the repository can be used for checking the results of different Analyzer or Constraint Verification runs.
After all, what's the use of the metrics if you can't look and compare them at later point of time.😄
Let's create a repository and see how these can be integrated to store the metrics:
# Initializing Metrics Repository: FileSystemMetricsRepository. Other Repositories are InMemoryMetricsRepository
from pydeequ.repository import FileSystemMetricsRepository, ResultKey
# Supports creating metrics file in S3 and HDFS
metrics_file = f"s3://{bucket_name}/nyc_tlc/pydeequ_metrics/ny_yellow_metrics.json"
nyc_yellow_repository = FileSystemMetricsRepository(spark, path = metrics_file)
print(metrics_file)Creating a FileSystemMetricsRepository that stores all the metrics in a file in S3.
Each set of metrics that we computed needs to be indexed by a so-called ResultKey, which contains a timestamp and supports arbitrary tags in the form of key-value pairs.
# This tag will uniquely identify the Analysis result
key_tags = {"tag": "nyc_yellow_oct_2023"}
resultKey = ResultKey(spark, ResultKey.current_milli_time(), key_tags)
verify_key_tag = {"tag": "verify_nyc_yellow_oct_2023"}
verify_resultKey = ResultKey(spark, ResultKey.current_milli_time(), verify_key_tag)Creating a ResultKey for analyzer and verification with different tags
Based on tags, you can store metrics of different runs within the same repository e.g. Verification Results on the different month's data (like nyc_yellow_repository can hold the Verification for metrics for Sep 2023, Oct 2023 and so on).Using Repositories with AnalysisRunner and Constraint Verification
# using .useRepository and saveOrAppendResult for saving results in metrics.json file
analysisResult = AnalysisRunner(spark) \
.onData(sample_df) \
.addAnalyzer(Size()) \
.addAnalyzer(Completeness("VendorID")) \
.addAnalyzer(Distinctness("VendorID")) \
.addAnalyzer(Uniqueness(["VendorID", "gen_id"])) \
.addAnalyzer(Compliance("payment_type", "payment_type in (1,2,3,4,5,6)")) \
.addAnalyzer(Mean("trip_distance")) \
.addAnalyzer(Sum("total_amount")) \
.addAnalyzer(Maximum("extra")) \
.useRepository(nyc_yellow_repository) \
.saveOrAppendResult(resultKey) \
.run()
analysisResult_df = AnalyzerContext.successMetricsAsDataFrame(spark, analysisResult)
analysisResult_df.show()Adding a Repository while doing Data Analysis
checkResult = VerificationSuite(spark) \
.onData(sample_df) \
.addCheck(
check.isComplete("VendorID") \
.isUnique("gen_id") \
.hasUniqueness(["VendorID", "gen_id"], assertion=lambda x: x==1) \
.hasCompleteness("Airport_fee", assertion=lambda x: x >= 0.95) \
.isNonNegative("fare_amount")) \
.useRepository(nyc_yellow_repository) \
.saveOrAppendResult(verify_resultKey) \
.run()
print(f"Verification Run Status: {checkResult.status}")
checkResult_df = VerificationResult.checkResultsAsDataFrame(spark, checkResult)
checkResult_df.show()Adding a Repository while running Constraints Verification
Reading metrics from Metrics Repository
ny_yellow_analysis_result = nyc_yellow_repository.load() \
.before(ResultKey.current_milli_time()) \
.getSuccessMetricsAsDataFrame()
ny_yellow_analysis_result.show()
Loading All Metrics written so far from the Repository
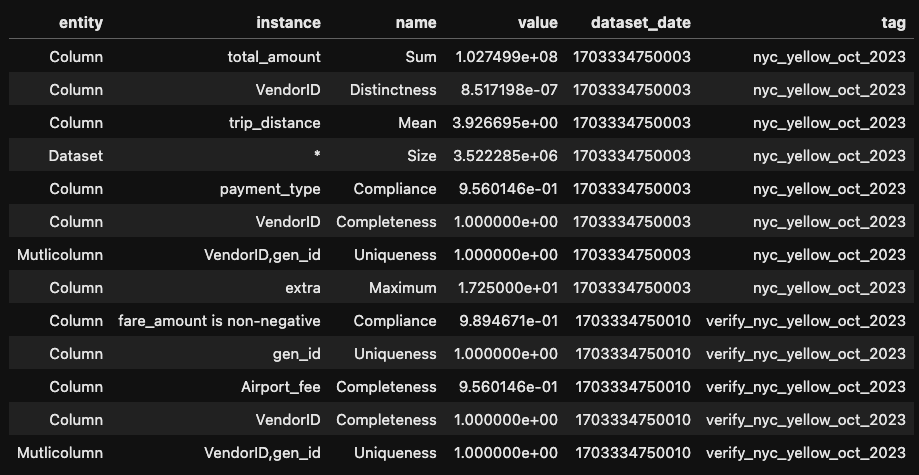
Filtering Repository Results based on Tag
You can use multiple filters to filter the repo based on tag and timestamp. We will be using filter results by tag here.
ny_yellow_verification = nyc_yellow_repository.load().withTagValues(verify_key_tag).getSuccessMetricsAsDataFrame()
ny_yellow_verification.show()Filtering results based on tag
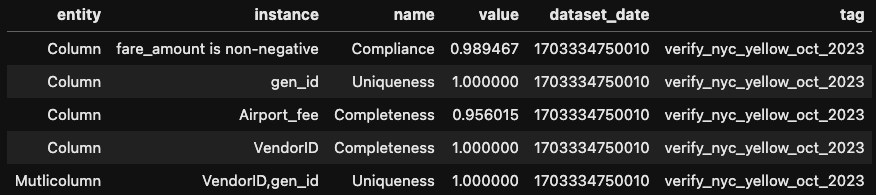
An important thing to know here: Metrics Repository only stores the metrics numbers along with the column and constraint details and NOT the Verification Results in case of Constraint Verification
So if you need to store the Verification Results, you can write those directly in a S3 Location or create an Athena table on top of it.
Here I will be creating an Athena table that will be used to store the Verification Results.
CREATE EXTERNAL TABLE `nyc_tlc.pydeequ_verification_results`(
`check` string,
`check_level` string,
`check_status` string,
`constraint` string,
`constraint_status` string,
`constraint_message` string
)
STORED AS PARQUET
LOCATION "s3://my-data-bucket/nyc_tlc/pydeequ_verification_results"Athena Verification Result Table definition
# Writing Verification Results into Athena Table
checkResult_df.write.insertInto("nyc_tlc.pydeequ_verification_results")Writing Verification Results into Athena Table
Querying in Athena
select * from nyc_tlc.pydeequ_verification_results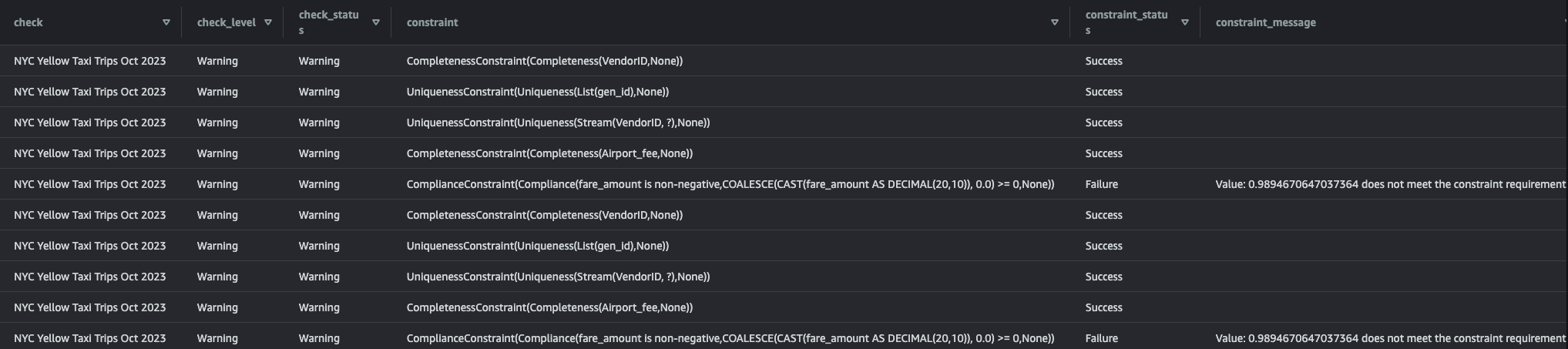
Reading metrics file from S3
As you can store your metrics.json file in S3 for later use, you can use the same file to create a FileSystemMetricsRepository
# metrics JSON file S3 Path
metrics_s3_path = "s3://{bucket_name}/nyc_tlc/pydeequ_metrics/ny_yellow_metrics.json"
repository_from_s3 = FileSystemMetricsRepository(spark, path = metrics_s3_path)
metrics_df = repository_from_s3.load() \
.before(ResultKey.current_milli_time()) \
.getSuccessMetricsAsDataFrame()
metrics_df.show()Creating Metrics Repository from S3 file
If you have read until here, please leave a comment below, and any feedback is highly appreciated. See you in the next post..!!! 😊
If it has added any value to you, consider subscribing, it's free of cost and you will get the upcoming posts into your mailbox too.





Member discussion