Building A Lightweight Spark Exception Logger
The general idea and main takeaways for you from this newsletter issue are NOT how I built a logger, but to give you an insight on:
- Need for such a solution,
- Design decisions made, and
- A working logger you can modify easily as needed, or even better, build your own logger.
In addition, to make it more than a logger dev newsletter issue, we will build a simple project to test it using Spark Standalone Cluster, MinIO Object Storage, and DuckDB.
Let's get right into it!!
What's the need for such a Logger?
The major issues currently when debugging Spark Applications, especially in production, are:
- Delays during the log aggregation
- Multiple-step process to fetch the logs
- Reviewing many log lines for minor issues like missing tables or columns or some missing variable causing syntax issues in your SQL, you get the idea.

tenorWhat if you can get the errors every time an application fails by querying a table or logging location?

tenorThis will save time, get your production jobs back up and running after failures, and avoid looking into logs until it's unclear from the logged Exception. In addition, this will enable Spark Application audits by identifying failures, performance issues (like Job time increase after some code release), etc.
Making Decisions for Logger Design
A logger should be:
- Easy to Integrate – Easier initialization so integrating it in already existing jobs are not painful or doesn't requires a regression testing.
- No Impact on Job Timings – It shouldn't impact the job timings. To make sure there are no performance degradation, it shouldn't involve any heavy lifting or operations, for e.g., taking the count of the output table at the same time. Main function should be just writing the logs.
- Lightweight – No additional package or dependency that needs to be build for it's deployment or working.
Provided that most of your jobs are written in functional programming way, creating a Decorator class @SparkExceptionLogger(...) makes more sense as it fulfills the 'Easy to Integrate' point as it will require just 1 line addition. Well 2 if you include import statement too.
What details should it Log?
Based on what we have discussed so far, the most important thing it should log is:
- Exception – column:
error - Exception Stacktrace/Description – column:
error_desc - Spark Application Id – column:
application_id - Start and End time – columns:
start_tsandend_ts - Execution Date – column:
execution_dt
In addition to this, while we are logging all these things, we can add:
- Time taken by each job – column:
time_taken - A Process or Sub Process name to get the idea of which process is impacted – column:
process_nameandsub_process - Spark Cluster ID, in case that changes daily for you. – column:
cluster_id
Alright, Let's Build now.
Building the Logger
If you are new to Python Decorators, you can give it a read here.
Decorator Class Initialization __init__
from os import popen, path
from pyspark.sql import Row
from datetime import datetime
# Defining Default LOG table and path
LOG_TABLE = "control_db.batch_logs"
LOG_PATH = "s3a://warehouse/logging/"
# Initializing Logger with required inputs
class SparkExceptionLogger:
def __init__(
self,
spark,
process_name,
script_name,
sub_process="",
service_name="",
log_to_path=False,
log_path="",
):
self.spark = spark
self.process_name = process_name
self.script = script_name
self.sprocess = sub_process
self.app_id = spark.sparkContext.applicationId
self.log_table = LOG_TABLE
self.service_name = service_name
self.path_logging = log_to_path
self.log_path = log_path if log_path else LOG_PATH
# Dictionary for creating a record that will be written
self.record_dict = {
"execution_dt": datetime.date(datetime.now()),
"process_name": self.process_name,
"sub_process": self.sprocess,
"script_name": self.script,
"cluster_id": self._get_hostname(),
"application_id": self.app_id,
"start_ts": datetime.now(),
}Decorator Class Initialization
Defining the Decorator Call method __call__
__call__ is the method that is called when the decorator is used. This is the method that wraps the actual method function call.
This is the place where we will fetch all the Exception details in case the method is failed and on successful run will just populate some column columns like end_ts , calculate time_taken etc.
def __call__(self, func):
def wrapper(*_args):
try:
# Actual function call
func(*_args)
# Updating the records dictionary on successful run
self.record_dict["status"] = "completed"
self.record_dict["end_ts"] = datetime.now()
self.record_dict["error"] = ""
self.record_dict["error_desc"] = ""
self._calculate_time_taken()
# write into log table or path
self._write_log()
except Exception as e:
# In case of exception, getting the exception details
self.record_dict["status"] = "failed"
self.record_dict["end_ts"] = datetime.now()
if hasattr(e, "getErrorClass"):
self.record_dict["error"] = (
e.getErrorClass() if e.getErrorClass() else e.__class__.__name__
)
else:
self.record_dict["error"] = e.__class__.__name__
if hasattr(e, "desc"):
self.record_dict["error_desc"] = e.desc
else:
self.record_dict["error_desc"] = str(e)
self._calculate_time_taken()
# write into log table
self._write_log()
raise e
return wrapperCall Method of Decorator Class
Helper methods
def _write_log(self):
"""Writes the log record into the log table"""
records = [Row(**self.record_dict)]
# Writing into table
if not self.path_logging:
col_order = self.spark.read.table(self.log_table).limit(1).columns
self.spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict")
self.spark.createDataFrame(records).select(*col_order).write.insertInto(
self.log_table
)
else:
self.spark.createDataFrame(records).write.mode("append").partitionBy(
"execution_dt"
).parquet(self.log_path)Write Logs Method to write the logs
def _calculate_time_taken(self):
"""Calculates the time taken to execute the function."""
start = self.record_dict["start_ts"]
end = self.record_dict["end_ts"]
diff = end - start
seconds_in_day = 24 * 60 * 60
mins, secs = divmod(diff.days * seconds_in_day + diff.seconds, 60)
time_taken = ""
if mins:
time_taken = time_taken + f"{mins} min"
if secs:
time_taken = time_taken + f"{secs} secs"
self.record_dict["time_taken"] = time_takenCalculating time-based on start_ts and end_ts
def _get_hostname(self):
"""Gets the hostname on which Spark job is running."""
return str(popen("hostname").read().strip())Method to get theDriver machine hostname
Combining all of these together creates our SparkExceptionLogger Decorator Class. You can find the final code here.
Let's build the project I mentioned at the beginning.
A Fun Baby Project
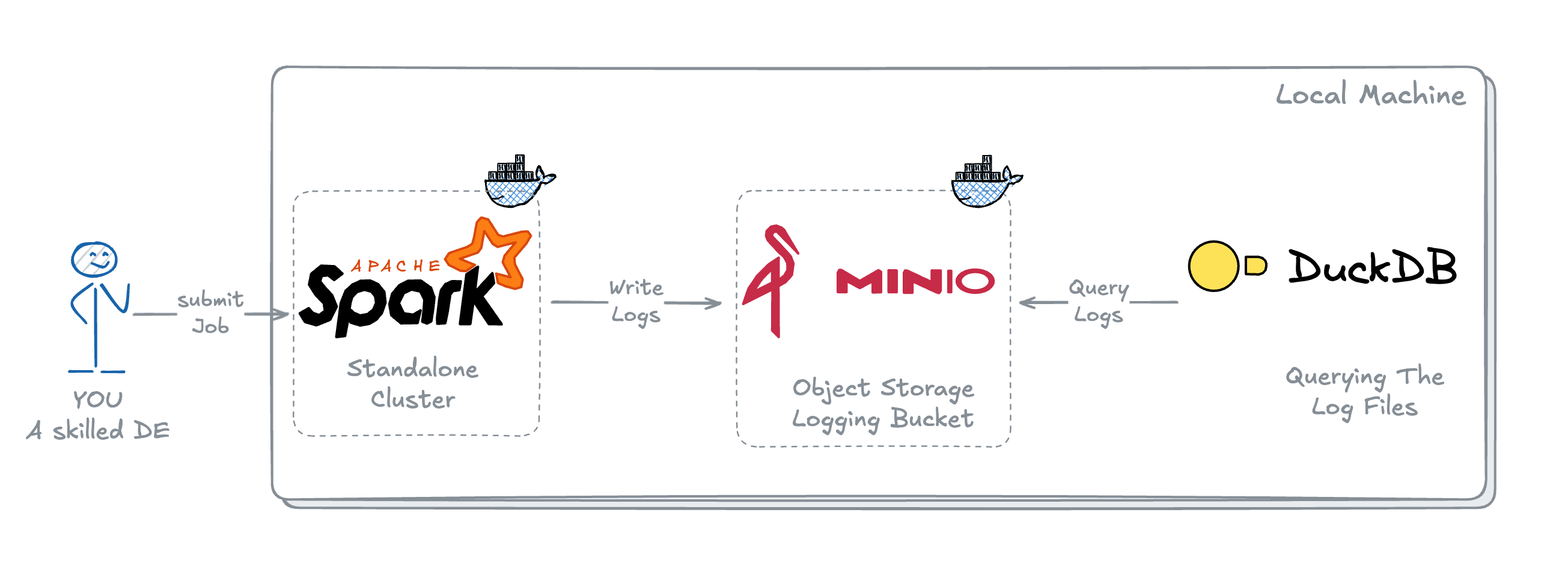
The general idea of this project is to have 3 components – Compute, Storage and a Query Engine.
In AWS, this could be: EMR/Glue, S3, and Athena
For Local, I chose: Spark, MinIO and DuckDB
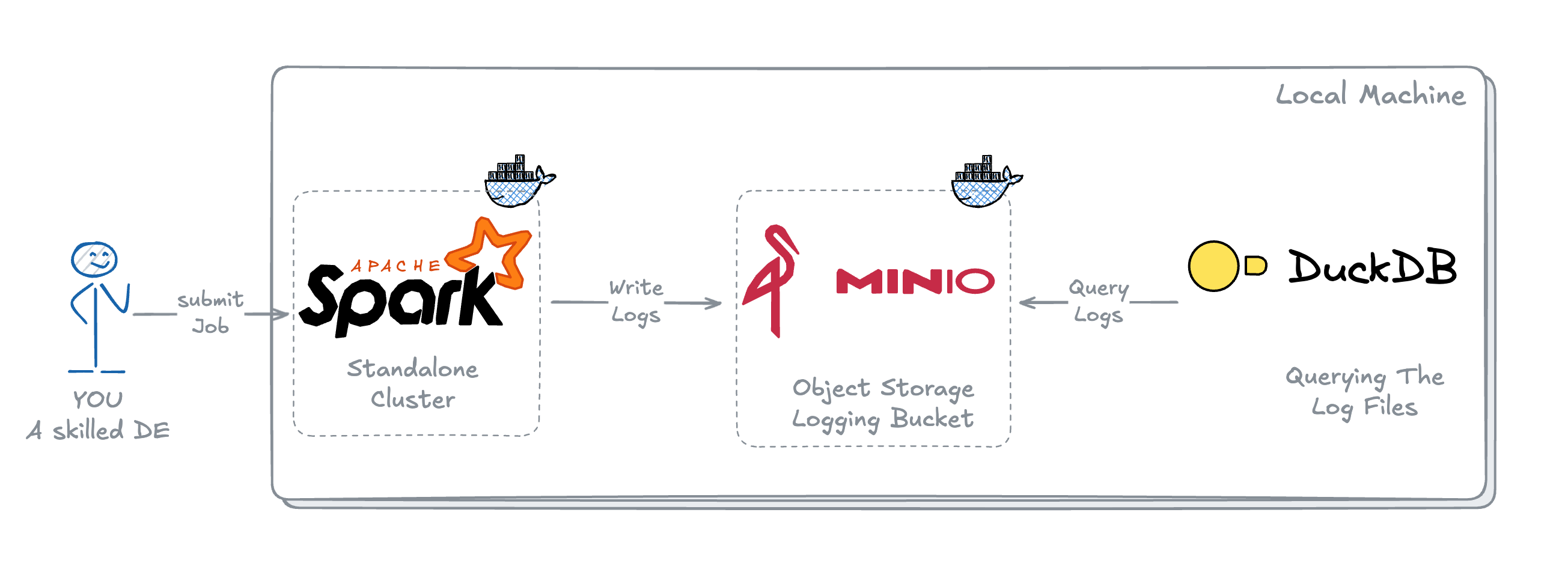
In this project as mentioned in Architecture above, we will be using:
- Standalone Spark Cluster running on Docker – Compute Engine for our jobs.
- MinIO running on Docker – MinIO is an Open Source Object Storage with APIs like AWS S3.
- DuckDB – an in-process SQL OLAP database, I chose DuckDB here because of 2 reasons:
- It's ability to query the files directly from S3 buckets and it's easy to get started without any hassle of additional management.
- It's one of the most popular database right now, and I want you to try it yourself once and you will see why.
I won't be going into the details of building a Docker image for Spark and MinIO in here (maybe an another blog if you are interested, let me know!!).
To keep it easier for you I have already created a GitHub repo that you can just clone and follow the instructions in README.md or the one I am going to go through.
Pre-requisites
- Make sure you have Docker Desktop installed in your laptop and is running.
- You have cloned the repo.
- DuckDB can be installed with just 1-2 lines. You can get it from here.
Starting everything up and running
Once you have everything in place, let's start with building and running all the Docker containers:
- Navigate to the cloned repo directory and build the Docker images
cd spark-minio-project
# On MacOS Run:
make build-nc
# On Windows/Linux Run:
docker compose build --no-cacheBuilding and Pulling Images for Docker Container
- Downloading all the required jars to interact with MinIO
bash ./jar-downloader.sh
# Incase you don't have bash shell,
# you can also download these jars directly from MVNRepositories
# place them into the spark-minio-project/jars folder
# Jars required:
## hadoop-aws-3.3.4.jar
## aws-java-sdk-bundle-1.12.262.jarDownloading required jars
- Running the Docker containers
# On Mac Run:
make run
# On Windows Run:
docker compose up Starting the Docker containers
Validating everything is up and running
Once everything is up and running, you will be able to see:
- Spark master running at
localhost:9090
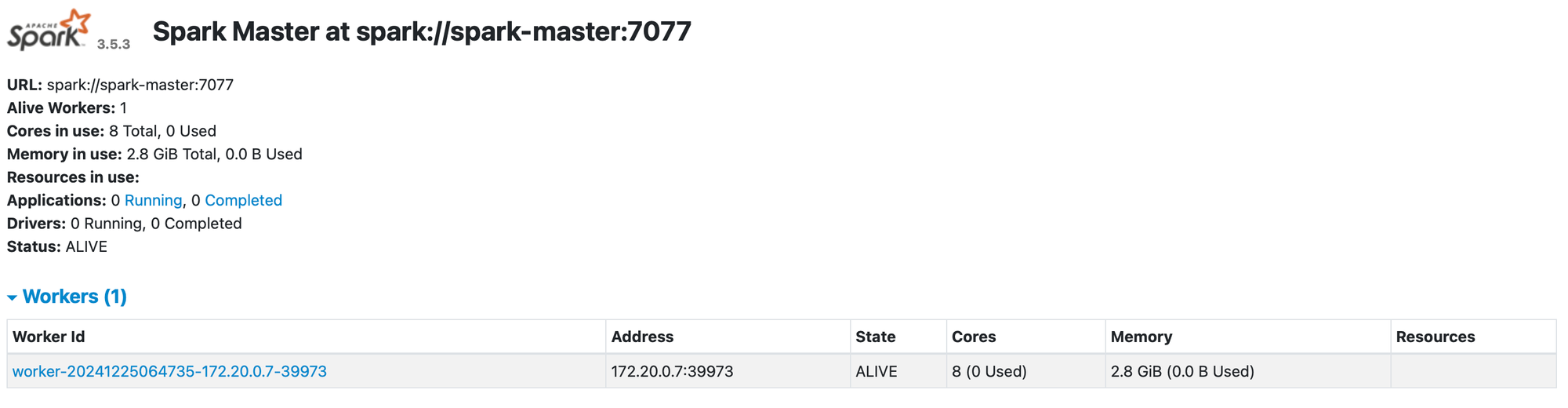
localhost:9090- MinIO UI running at
localhost:9001
Login using – Username:adminPassword:password
Make sure you have the warehouse bucket available withRead/WriteAccess, if not, you can create the same or another bucket.
localhost:9001- Place the
SparkExceptionLogger.pyinspark-minio-project/spark_appsfolder.
Creating a PySpark File with Logger integrated
Create a test script in spark-minio-project/spark_apps folder.
# test_spark_logger.py
from pyspark.sql import SparkSession
import os
from SparkExceptionLogger import SparkExceptionLogger
# Initializing Spark Session to be able to
# write to MinIO Bucket
spark = (
SparkSession.builder.master("spark://spark-master:7077")
.appName("spark-minio")
.config("spark.hadoop.fs.s3a.endpoint", os.environ.get("MINIO_ENDPOINT"))
.config("spark.hadoop.fs.s3a.access.key", os.environ.get("MINIO_ACCESS_KEY"))
.config("spark.hadoop.fs.s3a.secret.key", os.environ.get("MINIO_SECRET_KEY"))
.config("spark.hadoop.fs.s3a.path.style.access", "true")
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
.config(
"spark.hadoop.fs.s3a.aws.credentials.provider",
"org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider",
)
.getOrCreate()
)
process = "sales"
sub_process = "quaterly_sales"
@SparkExceptionLogger(
spark, process_name, __file__, sub_process=sub_process
service_name="local", log_to_path=True,
log_path="s3a://warehouse/logging/",
)
def main():
# Create a dataframe of sample data to write to the Iceberg table
df = spark.createDataFrame(
[
(1, "foo"),
(2, "bar"),
(3, "baz"),
],
["id", "value"],
)
# Writing into a non-existing table so that it fails explicitly
df.coalesce(1).write.insertInto("db.non_existing_table")
if __name__ == "__main__":
main()test_spark_logger.py Code to Test the Logger.
Submitting the Spark Job
To submit the Spark Job on running Spark Standalone Cluster, let's run a spark-submit on spark-master container:
# Running the spark-submit command on spark-master container
docker exec spark-master spark-submit --master spark://spark-master:7077 --deploy-mode client --jars /opt/extra-jars/hadoop-aws-3.3.4.jar,/opt/extra-jars/aws-java-sdk-bundle-1.12.262.jar --py-files ./apps/test_scripts/SparkExceptionLogger.py ./apps/test_spark_logger.pyspark-submit command to run test_spark_logger.py
If you notice the logs, you will have [TABLE_OR_VIEW_NOT_FOUND] Exception, just to make sure nothing else is breaking.
Querying the Logs from DuckDB
Time to start the quacking!! 🐥
- Start DuckDB using command-line on a terminal
# Creating a persistent Database File
duckdb minio_db.dbStarting duckdb on a terminal
- Creating a
SECRETto read from MinIO Bucket (similar to reading as from S3 Bucket)
CREATE SECRET minio_secrets (
TYPE S3,
KEY_ID 'admin', -- MINIO_USER
SECRET 'password', -- MINIO_PASSWORD
REGION 'us-east-1',
ENDPOINT '127.0.0.1:9000', -- MINIO_ENDPOINT
USE_SSL false,
URL_STYLE 'path'
);Creating a SECRET to interact with MinIO Bucket
┌─────────┐
│ Success │
│ boolean │
├─────────┤
│ true │
└─────────┘Output when SECRET creation is succssful
- Querying Logs from Log Location from Bucket
-- Reading Files Present in Log Location
-- hive_partitioning is provided as true
-- because we are writing data using partitionedBy
-- that creates directory structure in Bucket
FROM read_parquet('s3a://warehouse/logging/*/*.parquet', hive_partitioning = true);Querying Log Location from MinIO Bucket using DuckDB

┌──────────────┬────────────────┬──────────────────────┬──────────────┬──────────────────────┬───┬──────────────────────┬──────────────────────┬────────────┬──────────────┐
│ process_name │ sub_process │ script_name │ cluster_id │ application_id │ … │ error │ error_desc │ time_taken │ execution_dt │
│ varchar │ varchar │ varchar │ varchar │ varchar │ │ varchar │ varchar │ varchar │ date │
├──────────────┼────────────────┼──────────────────────┼──────────────┼──────────────────────┼───┼──────────────────────┼──────────────────────┼────────────┼──────────────┤
│ sales │ quaterly_sales │ /opt/spark/apps/te… │ 7a5350b4a095 │ app-20241225095304… │ … │ TABLE_OR_VIEW_NOT_… │ [TABLE_OR_VIEW_NOT… │ 1 secs │ 2024-12-25 │
├──────────────┴────────────────┴──────────────────────┴──────────────┴──────────────────────┴───┴──────────────────────┴──────────────────────┴────────────┴──────────────┤Output of Query from DuckDB
If you notice that we didn't use SELECT * while querying the table, that's because it's not mandatory when you want to see all the columns. Cool right ?!?
Just to see error or error_desc column, we can rewrite it like:
SELECT error, error_desc FROM read_parquet('s3a://warehouse/logging/*/*.parquet', hive_partitioning = true);Query to just get error and error_desc
If you notice in the output we can see the exact Exception in error and Stacktrace is stored in error_desc column.
A bit more on DuckDB
You can also change the way data is displayed on your duckdb cli by setting .mode before querying the data and you can create a file from the query output by using .ouput or .once.
-- .once just send the output of query once to the mentioned file
-- .output will send all the current and further query result to mentioned file until reset.
.mode json
.once logs.json
FROM read_parquet('s3a://warehouse/logging/*/*.parquet', hive_partitioning = true);
-- resetting to default mode
.mode duckboxGetting all logs in to a .json file
This will create a json file containing JSON a JSON array with each record as JSON object.
Shutting Down All the Docker Containers
To shut down all the containers
# On Mac
make down
# On Windows
docker compose down --volumes --remove-orphansShutting down all the running Docker containers
If you have followed along until here. Congratulations!!! You have:
- Figured out how to create your own logger.
- Deployed Spark and MinIO Docker containers that you can use as a playground for testing out various other concepts.
- Now know how to connect your DuckDB to query the S3 files directly without creating any table.
That's it for this one! 🚀 If you liked it, Leave a 🌟 on the repo,
Got any questions? Put it in the comments.
Member discussion