Shuffle-less Join, a.k.a Storage Partition Join in Apache Spark - Why, How and Where?

Say goodbye to expensive shuffles in Spark! With the Storage Partition Join (SPJ) optimization technique in Spark >= 3.3 (more matured in 3.4), you can perform joins on partitioned Data Source V2 tables without triggering a shuffle (of course, some conditions apply).
Shuffles are expensive, especially in joins in Spark, mainly because:
- Shuffle requires data transfer across the network, which is CPU intensive.
- During shuffling, Shuffle files are written into a local disk, and it's Disk I/O Expensive.
Data Source V2 tables are Open Format Tables, i.e., Apache Hudi, Apache Iceberg, and Delta Lake Tables.
This blog post will cover:
- What are the requirements for SPJ to work?
- What configurations needs to be set for SPJ to work?
- How to check whether SPJ is working or not for your Spark Job?
- Diving Deeper into SPJ by understanding the configurations being set.
You can download it locally to follow along.
Let's get started!!

Requirements for SPJ
- Both the target and source must be Iceberg Tables.
- Both the source and target tables should have the same partitioning (at least one of the partitioning columns should be the same)
- The join condition must include the partition column.
- Configurations must be appropriately set.
- Apache Iceberg Version >= 1.2.0 and Spark version >= 3.3.0
Configurations
spark.sql.sources.v2.bucketing.enabledset totruespark.sql.sources.v2.bucketing.pushPartValues.enabledset totruespark.sql.iceberg.planning.preserve-data-groupingset totruespark.sql.requireAllClusterKeysForCoPartitionset tofalsespark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabledset totrue
Partitioning Keys and Clustering Keys refer to the same concept and can be used interchangeably. Please do not confuse them.
I will be using Spark 3.5.0 with Iceberg 1.5.0 for this.
Before we get into SPJ, let's create some mock data and look into how the Spark join plan actually looks when SPJ is not working:
Initializing SparkSession
We will be initializing a Spark Session with all the Iceberg related configs but without SPJ configs first:
from pyspark.sql import SparkSession, Row
# update here the required versions
SPARK_VERSION = "3.5"
ICEBERG_VERSION = "1.5.0"
CATALOG_NAME = "local"
# update this to your local path where you want tables to be created
DW_PATH = "/path/to/local/warehouse"
spark = SparkSession.builder \
.master("local[4]") \
.appName("spj-iceberg") \
.config("spark.sql.adaptive.enabled", "true")\
.config('spark.jars.packages', f'org.apache.iceberg:iceberg-spark-runtime-{SPARK_VERSION}_2.12:{ICEBERG_VERSION},org.apache.spark:spark-avro_2.12:3.5.0')\
.config('spark.sql.extensions','org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')\
.config(f'spark.sql.catalog.{CATALOG_NAME}','org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{CATALOG_NAME}.type','hadoop') \
.config(f'spark.sql.catalog.{CATALOG_NAME}.warehouse',DW_PATH) \
.config('spark.sql.autoBroadcastJoinThreshold', '-1')\
.enableHiveSupport()\
.getOrCreate()SparkSession initialization without SPJ required configs
Preparing Data
We will be creating and writing data into 2 Iceberg tables:
- Customers and Orders both tables are partitioned/clustered by
region - Both can be joined using the
customer_idand includes the region details and some other common details like Name, Email etc.
Data is being mocked up using Faker python library. In case, if you don't have it:
pip install faker# Creating Mockup data for Customers and Orders table.
from pyspark.sql import Row
from faker import Faker
import random
# Initialize Faker
fake = Faker()
Faker.seed(42)
# Generate customer data
def generate_customer_data(num_customers=1000):
regions = ['North', 'South', 'East', 'West']
customers = []
for _ in range(num_customers):
signup_date = fake.date_time_between(start_date='-3y', end_date='now')
customers.append(Row(
customer_id=fake.unique.random_number(digits=6),
customer_name=fake.name(),
region=random.choice(regions),
signup_date=signup_date,
signup_year=signup_date.year # Additional column for partition evolution
))
return spark.createDataFrame(customers)
# Generate order data
def generate_order_data(customer_df, num_orders=5000):
customers = [row.customer_id for row in customer_df.select('customer_id').collect()]
orders = []
for _ in range(num_orders):
order_date = fake.date_time_between(start_date='-3y', end_date='now')
orders.append(Row(
order_id=fake.unique.random_number(digits=8),
customer_id=random.choice(customers),
order_date=order_date,
amount=round(random.uniform(10, 1000), 2),
region=random.choice(['North', 'South', 'East', 'West']),
order_year=order_date.year # Additional column for partition evolution
))
return spark.createDataFrame(orders)
# Generate the data
print("Generating sample data...")
customer_df = generate_customer_data(1000)
order_df = generate_order_data(customer_df, 5000)
customer_df.show(5, truncate=False)
order_df.show(5, truncate=False)Preparing Data for Customers and Orders table
Writing Data into Iceberg Tables
customer_df.writeTo("local.db.customers") \
.tableProperty("format-version", "2") \
.partitionedBy("region") \
.create()
order_df.writeTo("local.db.orders") \
.tableProperty("format-version", "2") \
.partitionedBy("region") \
.create()Writing the generated data into Customers and Orders table
Joining tables without SPJ Config enabled
CUSTOMERS_TABLE = 'local.db.customers'
ORDERS_TABLE = 'local.db.orders'
cust_df = spark.table(CUSTOMERS_TABLE)
order_df = spark.table(ORDERS_TABLE)
# Joining on region
joined_df = cust_df.join(order_df, on='region', how='left')
# Generated plan from
joined_df.explain("FORMATTED")
# triggering an action
joined_df.show(1)Join BEFORE - SPJ Config Enabled
== Physical Plan ==
AdaptiveSparkPlan (9)
+- Project (8)
+- SortMergeJoin LeftOuter (7)
:- Sort (3)
: +- Exchange (2)
: +- BatchScan local.db.customers (1)
+- Sort (6)
+- Exchange (5)
+- BatchScan local.db.orders (4)Spark Query Plan when SPJ is not working - Exchange node is present for both the tables
Exchange Node in the plan above represents the shuffle.
If you are more of an Spark UI person, then this can also be seen there.
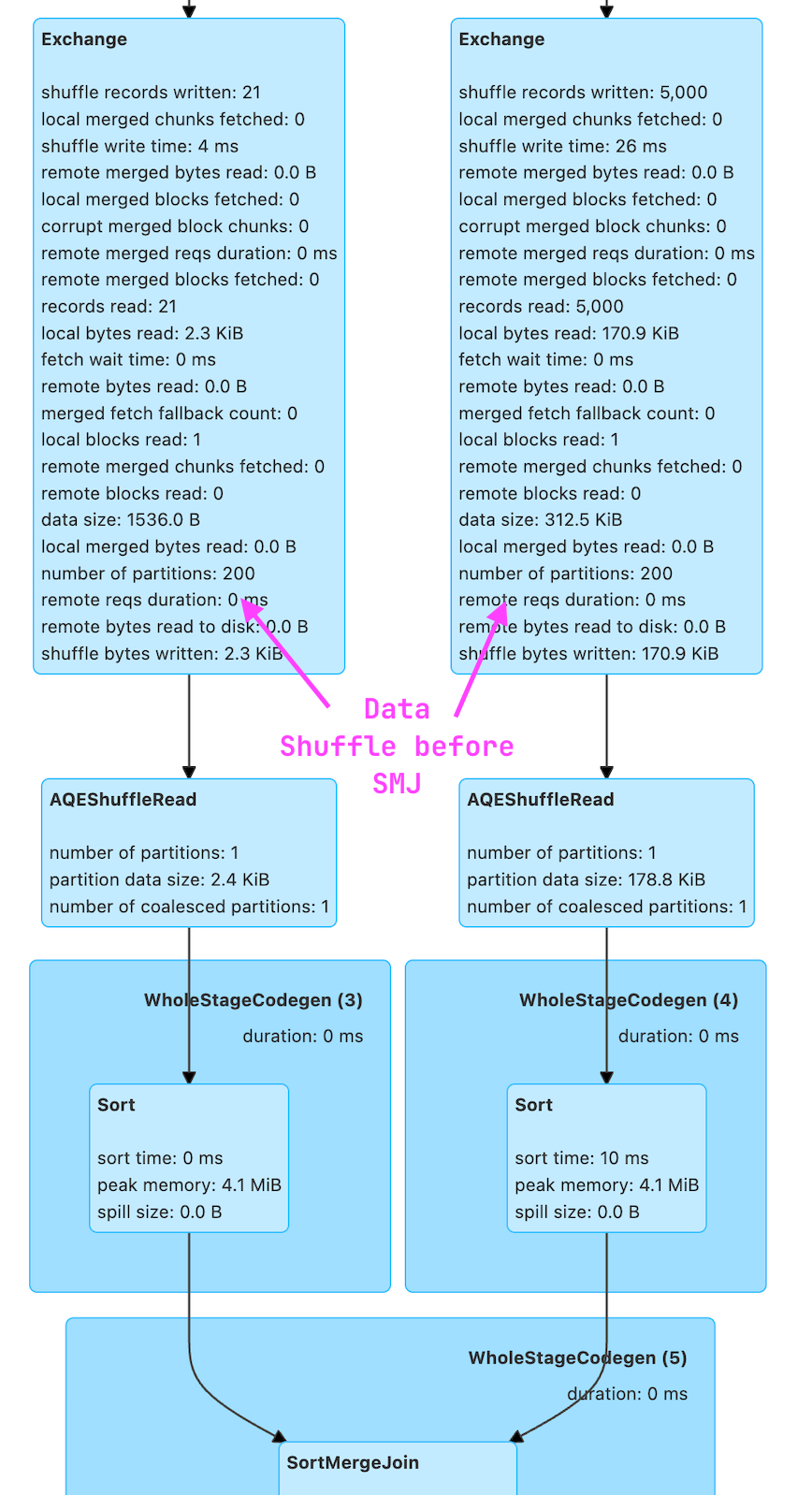
Join with SPJ Enabled
Let's enable the SPJ required configurations
# Setting SPJ related configs
spark.conf.set('spark.sql.sources.v2.bucketing.enabled','true')
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
spark.conf.set('spark.sql.iceberg.planning.preserve-data-grouping','true')
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
spark.conf.set('spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled','true')Setting SPJ required configs
Let's perform the same join again and look into the plan and Spark UI
joined_df = cust_df.join(order_df, on='region', how='left')
joined_df.explain("FORMATTED")
joined_df.show()Join after SPJ configs are enabled
== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)Physical Plan of the join after SPJ configs enabled
There are no Exchange nodes present in the plan and that means NO SHUFFLE!!!

Let's take a look at Spark UI too.
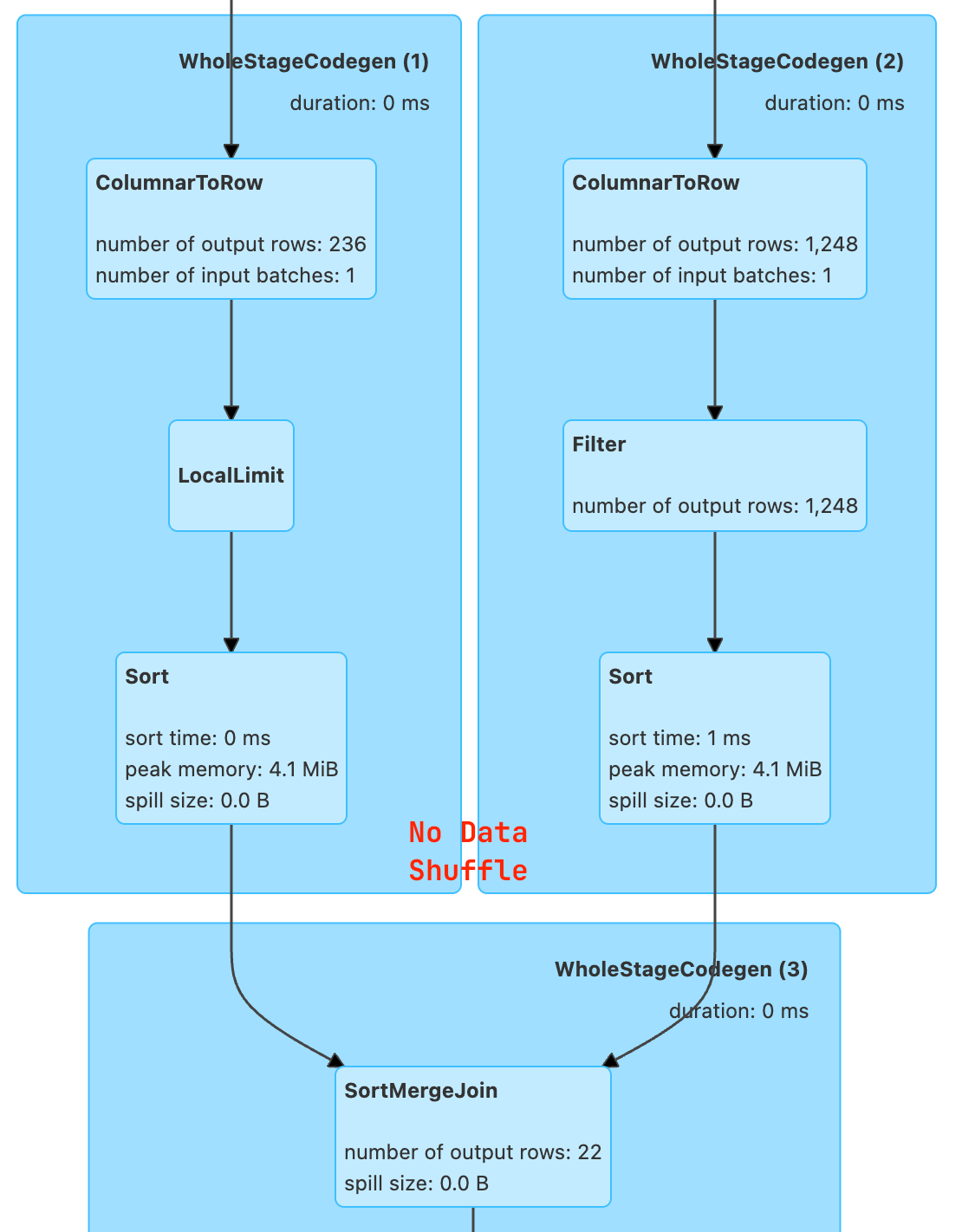
EXCHANGE nodes.Now that's amazing but hey, yo, wait, that's the ideal scenario where we have our tables are partitioned the same way and join is only using partitioned column. In real world scenario that's hardly the case.
Valid Point! Let's dive a bit deeper to see how it works and see some similar joining conditions as real case scenarios to check if SPJ is gonna work.
Understanding Configurations used in SPJ
A Storage Partitioned Join makes use of the existing storage layout to avoid the shuffle phase.
The must and minimum requirement for SPJ to work is setting the configurations that can provide this information, i.e.
spark.sql.iceberg.planning.preserve-data-grouping
When true, partitioning info is retained during query planning. This prevents unnecessary repartitioning, optimizing performance by reducing shuffle costs during execution.
spark.sql.sources.v2.bucketing.enabled
When true, try to eliminate shuffle by using the partitioning reported by a compatible V2 data source.
Let's look at the various join scenarios:
Scenario 1: Joining keys same as Partitioning keys
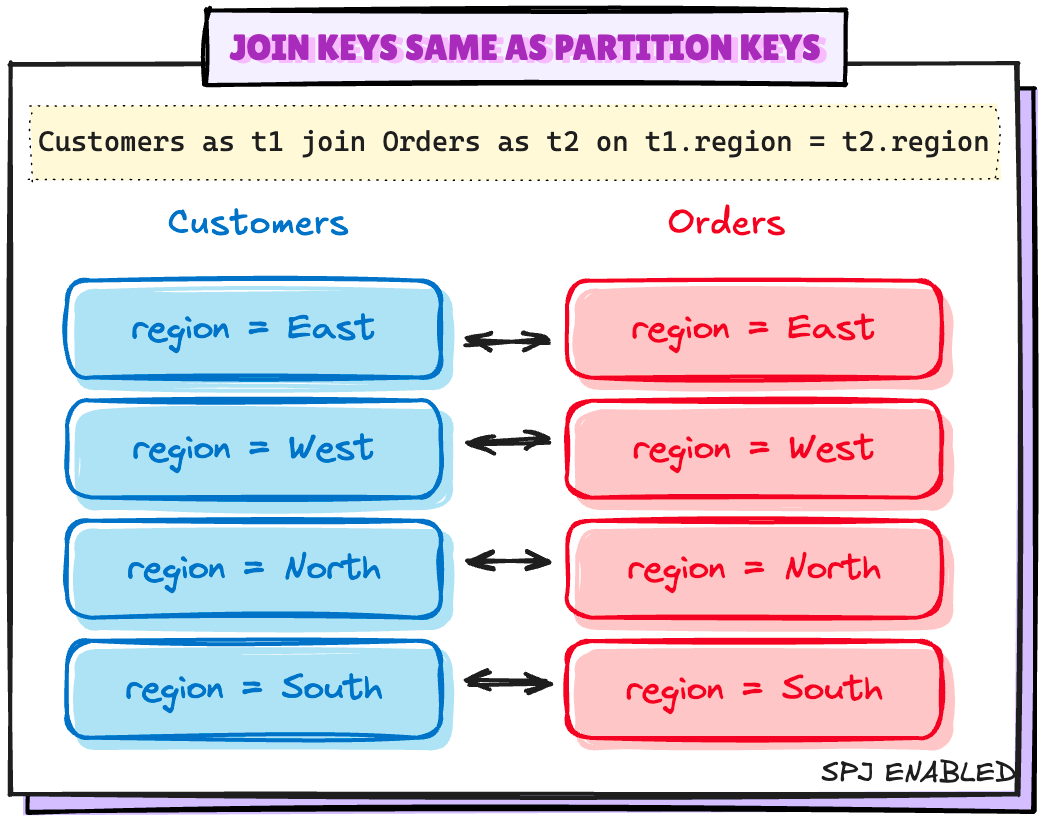
# Setting up the minimum configuration for SPJ
spark.conf.set("spark.sql.sources.v2.bucketing.enabled", "true")
spark.conf.set("spark.sql.iceberg.planning.preserve-data-grouping", "true")
joined_df = cust_df.join(order_df, on="region", how="left")
joined_df.explain("FORMATTED")Joining with minimal SPJ configurations
== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)Plan with NO Exchange Node
No Exchange Nodes in the plan. So minimal configuration works in this case. 🥳
Scenario 2: Partitions from both side doesn't match
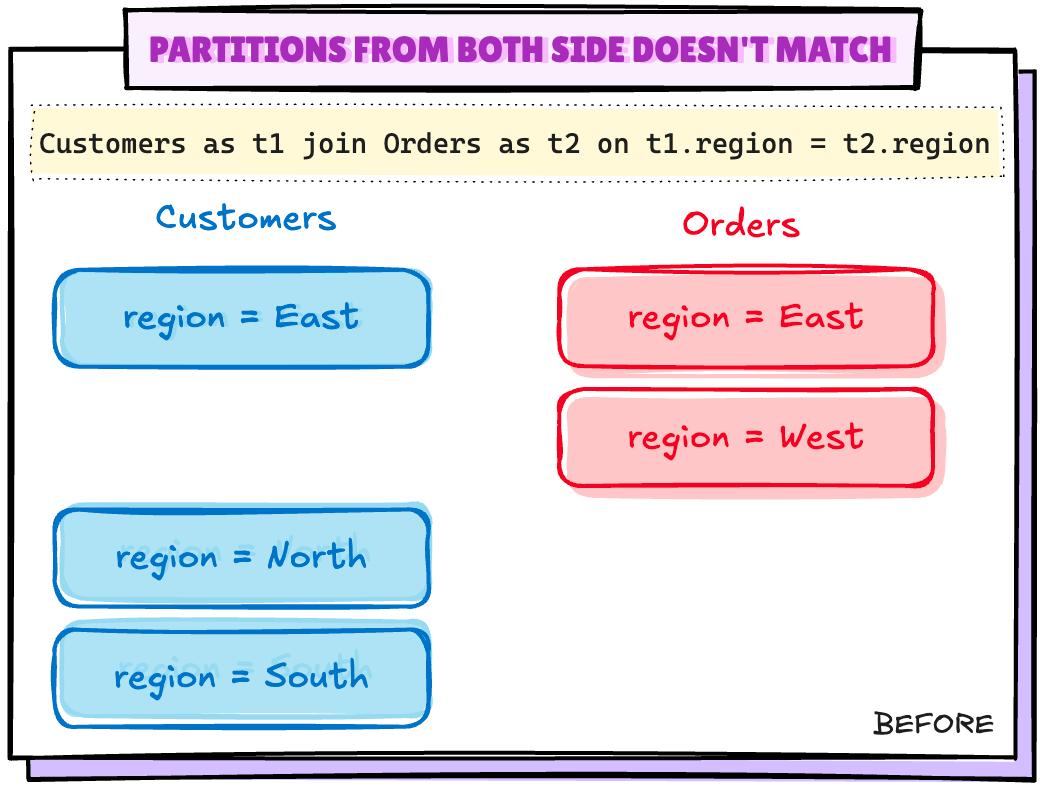
Let's create this kind of scenario by dropping one partition from Orders table
# Deleting all the records for a region
spark.sql("DELETE FROM {ORDERS_TABLE} where region='West'")
# Validating if the partition is dropped
orders_df.groupBy("region").count().show()Deleting all the records from a region
+------+-----+
|region|count|
+------+-----+
| East| 1243|
| North| 1267|
| South| 1196|
+------+-----+
Let's check the plan now for the same joining condition
joined_df = cust_df.join(order_df, on="region", how="left")
joined_df.explain("FORMATTED")Join with SPJ Enabled with minimum configuration
== Physical Plan ==
AdaptiveSparkPlan (9)
+- Project (8)
+- SortMergeJoin LeftOuter (7)
:- Sort (3)
: +- Exchange (2)
: +- BatchScan local.db.customers (1)
+- Sort (6)
+- Exchange (5)
+- BatchScan local.db.orders (4)Plan when the partitions are missing. Exchange is back.!!
Exchange (Shuffle) is back again..‼️ 🤨
To handle such scenarios, Spark creates empty partition for the missing partition values after enabling the mentioned configuration:
spark.sql.sources.v2.bucketing.pushPartValues.enabled
When enabled, try to eliminate shuffle if one side of the join has missing partition values from the other side.
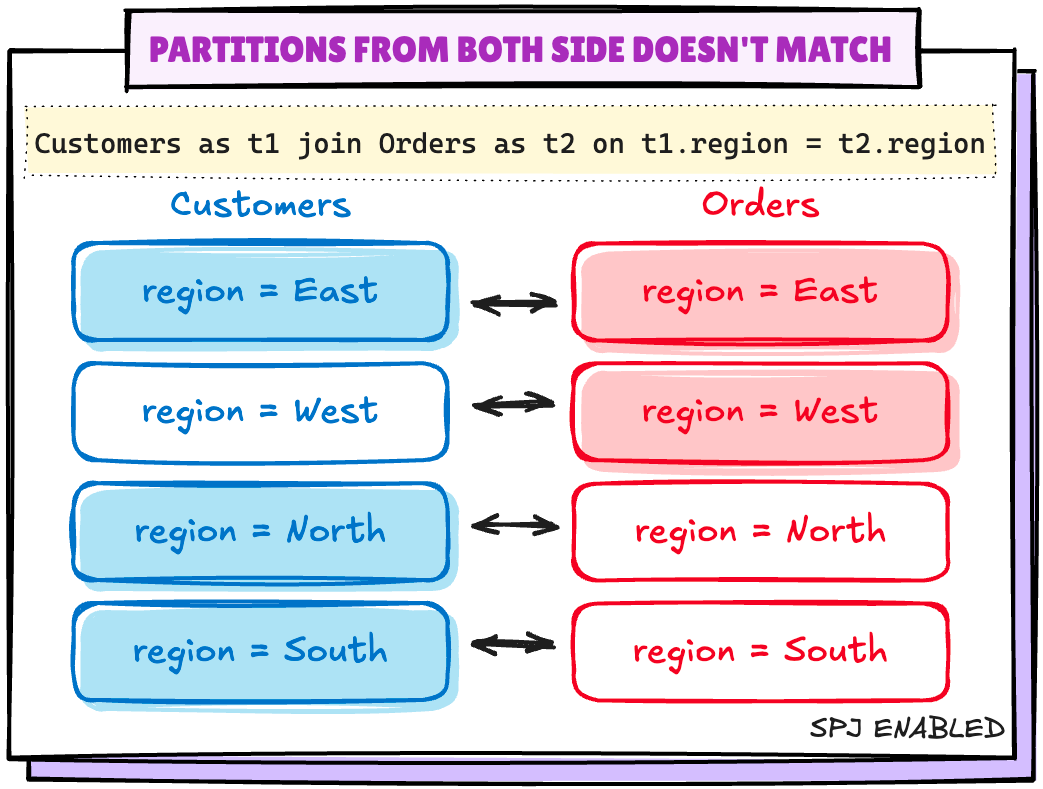
EMPTY partitions created by Spark# Enabling config when there are missing partition values
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
joined_df = cust_df.join(order_df, on='region', how='left')
joined_df.explain("FORMATTED")Join after enabling pushPartValues config
== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)Plan after enabling pushPartValues config.
No more shuffle..!! 🥳
Scenario 3: Join Keys do not match the Partition Keys
This scenario can have one of these 2 cases:
- Join Keys are superset of Partition Keys
- Join Keys are subset of Partition Keys
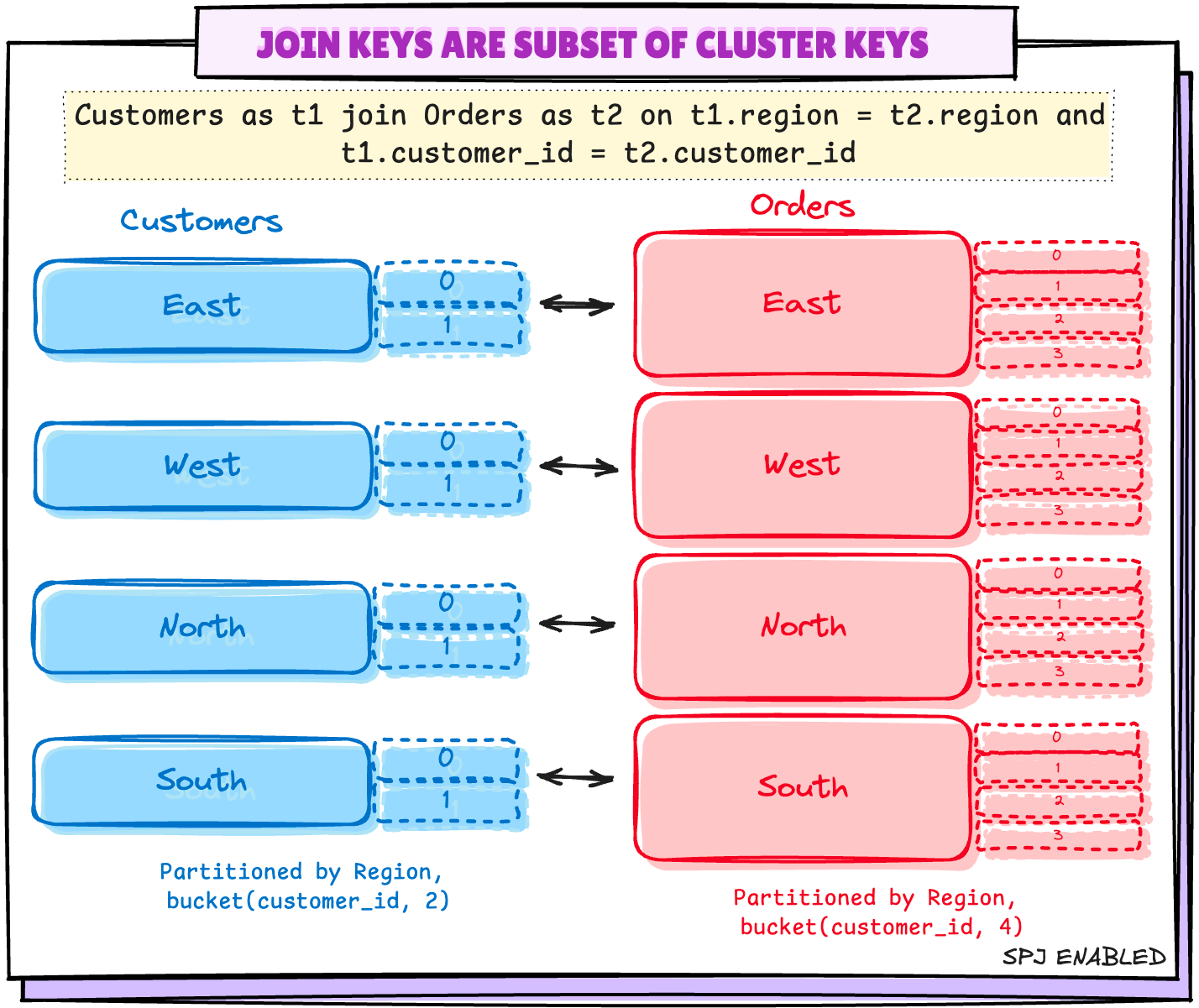
3.1 Join Keys are superset of Partition Keys
These are the queries with additional field in join along with Partition Keys like:
Select * from Customers as t1
join
Orders as t2
on t1.region = t2.region
and
t1.customer_id = t2.customer_id -- additional column `customer_id`Additional column in joins
By default, Spark requires all the partition keys should be same and in order to eliminate the shuffle. This behavior can be turned off using:
spark.sql.requireAllClusterKeysForCoPartition
When true, require the join or MERGE keys to be same and in the same order as the partition keys to eliminate shuffle.
That's the reason it's being set tofalse
# Setting up another config to support SPJ for these cases
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
joined_df = cust_df.join(order_df, on=['region','customer_id'], how='left')
joined_df.explain("FORMATTED")Join after setting requireAllClusterKeysForCoPartition to false
== Physical Plan ==
AdaptiveSparkPlan (8)
+- Project (7)
+- SortMergeJoin LeftOuter (6)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (5)
+- Filter (4)
+- BatchScan local.db.orders (3)Plan after setting requireAllClusterKeysForCoPartition to false
No Shuffle..!!! 🥳
3.2 Join Keys are subset of Partition Keys
These can be the scenarios where tables are not partitioned the same way, like in the below:
- Customers table is partitioned by
regionandbucket(customer_id,2) - Orders table is partitioned by
regionandbucket(customer_id, 4)
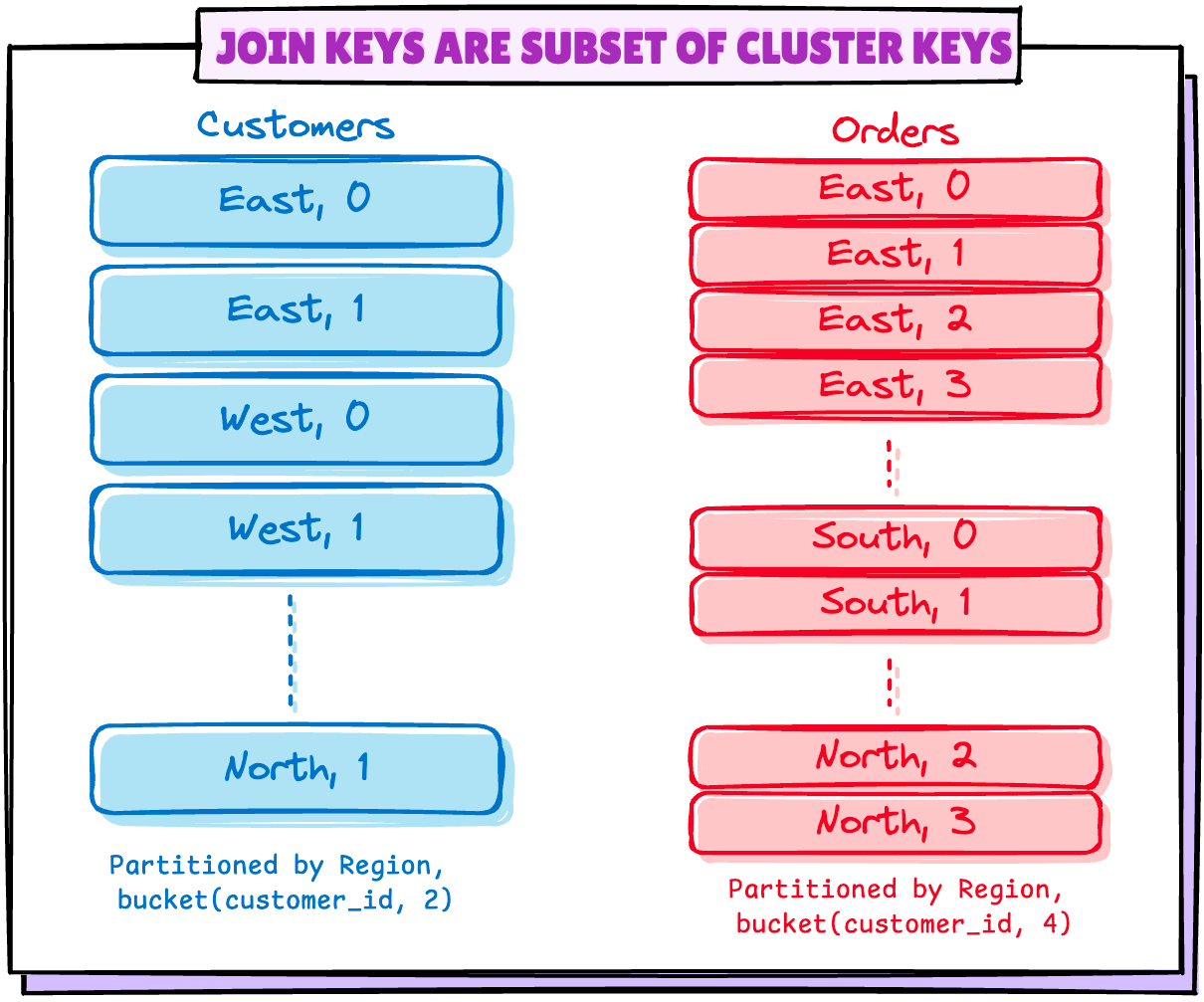
Customers and Orders TableOr the cases where tables are partitioned on multiple columns and join uses only few of them to join.
In such cases, Spark 4.0 groups the input partitions on column regions something like below:
Spark 4.0 provides a configuration to enable this –spark.sql.sources.v2.bucketing.allowJoinKeysSubsetOfPartitionKeys.enabled
When enabled, try to avoid shuffle if join condition does not include all partition columns.
// Spark 4.0 SPJ Subset Join Keys test
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
object SPJTest {
def main(args: Array[String]): Unit = {
// SparkSession creation
val spark = SparkSession.builder......
//Setting all SPJ configs available in Spark 3.4.0
spark.conf.set("spark.sql.sources.v2.bucketing.enabled","true")
spark.conf.set("spark.sql.iceberg.planning.preserve-data-grouping","true")
spark.conf.set("spark.sql.sources.v2.bucketing.pushPartValues.enabled",
"true")
spark.conf.set("spark.sql.requireAllClusterKeysForCoPartition","false")
// Configuration from Spark 4.0
spark.conf.set("spark.sql.sources.v2.bucketing.allowJoinKeysSubsetOfPartitionKeys.enabled", "true")
// CUSTOMER table partitioned on region, year(signup_date), bucket(2, customer_id)
// ORDER table partitioned on region, year(order_date), bucket(4, customer_id)
val CUSTOMER_TABLE = "local.db.customers_buck"
val ORDERS_TABLE = "local.db.orders_buck"
val cust_df = spark.table(CUSTOMER_TABLE)
val orders_df = spark.table(ORDERS_TABLE)
// join cust_df and orders_df on region alone
val joined_df = cust_df.alias("cust")
.join(orders_df.alias("ord"),
col("cust.region") === col("ord.region"),
"left")
println(joined_df.explain("FORMATTED"))Spark 4.0 Scala code to test SPJ Join Subset
== Physical Plan ==
AdaptiveSparkPlan (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers_buck (1)
+- Sort (4)
+- BatchScan local.db.orders_buck (3)Plan with SPJ enabled
Scenario 4: Data Skewness in Partitions
This is of major concern if you are running a heavy workload where data skewness is pretty common. Let's say your data distribution looks something like this:
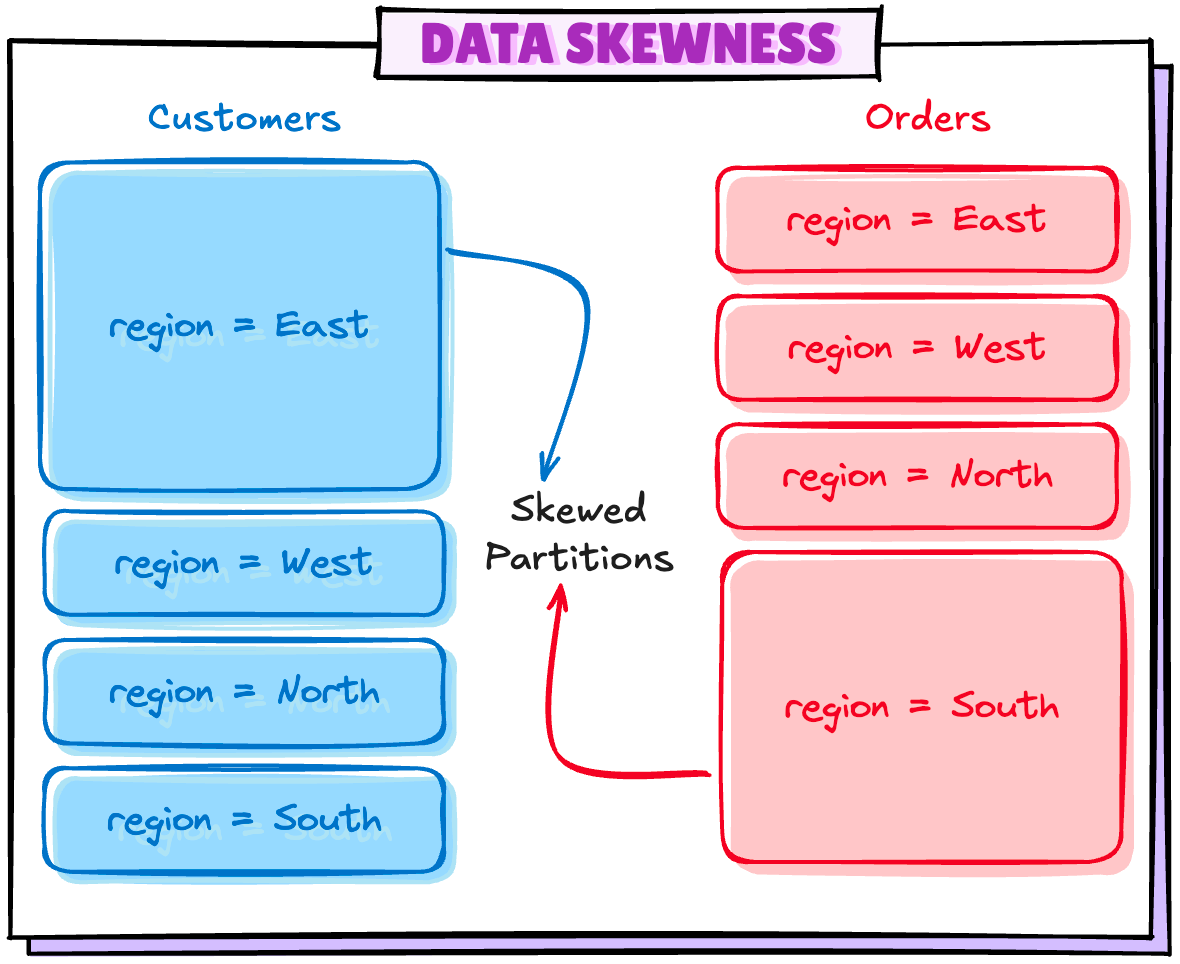
Unfortunately, I couldn't replicate this scenario even after multiple tries, so this has to be theoretical and maybe I will update it in future as soon as I can replicate this.
So, theoretically, sparks provides a configuration:
spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled
When true, and when the join is not a full outer join, enable skew optimizations to handle partitions with large amounts of data when avoiding shuffle.
With this configuration enabled, Spark breaks the skewed partitions into multiple splits and the other side of same partition will be grouped and replicated to match the same.
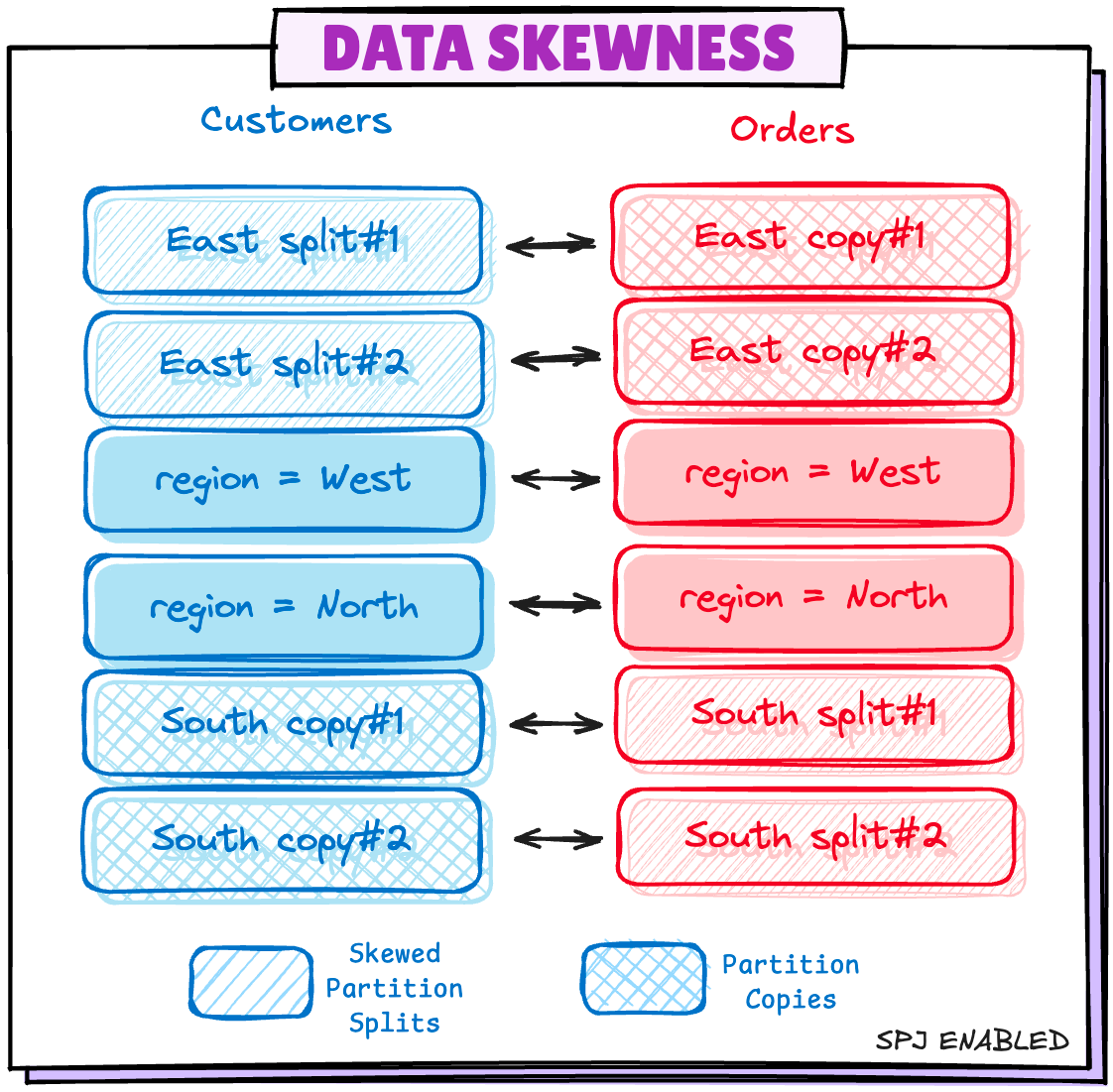
Skewed region=East partition from Customers table is split into 2 small partitions, on Orders table side, 2 copies of region=East are created.
That's it for this one!! 🚀
If you have read it until here, you are equipped with all the knowledge you need to know where SPJ can be used in your job.
Got any questions? Put it in the comments.
References
[1] Storage Partitioned Join Design Doc
[2] Spark PR for SPJ
[3] Spark PR for Partially Clustered Distribution
[4] Spark 4.0.0 preview2 documentation
If you found this valuable and want more content like this, subscribe to the newsletter—every post is carefully crafted to be worth your time!



Member discussion