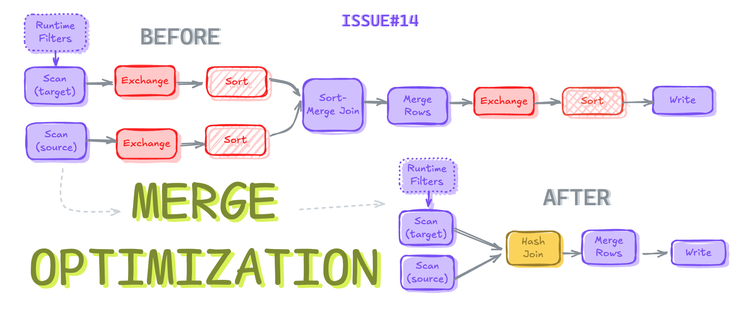
Optimizing Iceberg MERGE Statements
How can you eliminate shuffling, sorting, and push-down filters to optimize the Apache Iceberg merge statements?
How withColumn Can Degrade the Performance of a Spark Job?
Reasons and Solutions to Avoid Performance Degradation due to excessive use of `.withColumn()` in Apache Spark
Shuffle-less Join, a.k.a Storage Partition Join in Apache Spark - Why, How and Where?
A Deep Dive into Shuffle-less joins (Storage Partitioned Joins) in Apache Spark to improve Join performance when using V2 Data Sources.