Write-Audit-Publish Pattern with Apache Iceberg on AWS using Branches

This blog will cover how to implement a Write-Audit-Publish (WAP) Data Quality Pattern in AWS using Apache Spark on EMR that uses AWS Glue Catalog as metastore for the Apache Iceberg table and AWS Athena for querying the table.
This blog uses EMR 6.15, comes with Apache Spark 3.4 and, supports Apache Iceberg version 1.4.0
What is Write-Audit-Publish?
Write-Audit-Publish (WAP) is a data quality pattern commonly used in the data engineering workflow that helps us validate datasets by allowing us to write data to a staged snapshot/branch of the production table and fix any issues before finally committing the data to the production tables.
WAP in Action using Iceberg Table's Branching feature
Pre-requisites for following along
An EMR running with Iceberg Cluster along with Spark 3.4 and Iceberg version > 1.2
The data that I will be using in this blog post is NYC Yellow Taxi Trip Data
When you are creating an EMR Cluster make sure, you Edit Software Setting > Enter Configuration
[{
"Classification":"iceberg-defaults",
"Properties":{"iceberg.enabled":"true"}
}]Software Configuration while Creating EMR
Preparing Table and Data for WAP
Let's start with setting up all the configurations that we need in SparkSession for this implementation to work.
%%configure
{
"conf": {
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"spark.sql.catalog.glue": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.glue.catalog-impl":"org.apache.iceberg.aws.glue.GlueCatalog",
"spark.sql.catalog.glue.io-impl":"org.apache.iceberg.aws.s3.S3FileIO",
"spark.sql.catalog.glue.warehouse":"s3://bucket-name/glue/warehouse"
}
}SparkSession Configuration on Jupyter Notebook.
In the case of a spark script, you can set these configurations while creating yourSparkSessionusingSparkSession.builder.config("config-key", "config-value")orspark.conf.set("config-key", "config-value")
Understanding Spark Configurations for Iceberg
spark.sql.extensions- For loading Iceberg's SQL Extensions module. This module lets you execute variousSpark Proceduresand additionalALTERstatements forAdd/Drop/Replace Partitions,Set Write Order, Write Distributionand a few other things that are not possible without these extensions. We will be using this to call a Spark Procedure in WAPspark.sql.catalog.glue- Defines a catalog name. In this caseglueis acatalog-nameand the valueorg.apache.iceberg.spark.SparkCatalogmentions an Iceberg Catalog for Sparkspark.sql.catalog.glue.catalog-impl- Ascatalogin Iceberg is an interface and has multiple implementations, this property defines which implementation needs to be used. In our case, it'sGlueCatalog.spark.sql.catalog.glue.io-impl- Read/Write implementation for the catalog, as AWS Glue Catalog refers to AWS S3, we will be usingS3FileIOfor reading and writing from S3.spark.sql.catalog.glue.warehouse- This is the base path in the S3 location where all the data and metadata will be stored by default. This is mainly overwritten during runtime, in case you have an AWS Glue Catalog Database that has a pre-defined S3 location or a pre-defined tableLocationpresent in it.
In case you are writing a new Iceberg table without mentioning theLocation, this table data will be written into a location defined in this property.
Let's create an Iceberg Table that we will consider as a main Production Table on which we will implement WAP to write some new data from the Source Table.
from pyspark.sql.functions import lit, col
# Reading NYC Yellow Taxi Data for Sep 2023
raw_data_path = "s3://my-data-bucket/raw_data/nyc_tlc"
yellow_df = spark.read.format("parquet").load(f"{raw_data_path}/yellow/sep2023/")
# adding year and month column
yellow_df = yellow_df.withColumn("month", lit(9)) \
.withColumn("year", lit(2023))Reading Sep 2023 Yellow Taxi Trip Data for creating Production Iceberg Table
# creating an Iceberg table in glue catalog within nyc_tlc database. default compression is taken as 'zstd'
prod_table = "glue.nyc_tlc.yellow_taxi_trips"
yellow_df.writeTo(prod_table).partitionedBy("year", "month") \
.using("iceberg") \
.tableProperty("format-version", "2") \
.tableProperty("write.parquet.compression-codec", "snappy") \
.create()Writing data to create a Production Table called yellow_taxi_trips
## Check data into prod table
spark.table(prod_table).groupBy("year", "month").count().show()Verifying data into Production Table
+----+-----+-------+
|year|month| count|
+----+-----+-------+
|2023| 9|2846722|
+----+-----+-------+Output
Athena only supports Iceberg Table v2 tables. This is something to keep in mind if you are using Athena as query engine.
show create table nyc_tlc.yellow_taxi_trips
-- Result
CREATE TABLE nyc_tlc.yellow_taxi_trips (
VendorID int,
tpep_pickup_datetime timestamp,
tpep_dropoff_datetime timestamp,
passenger_count bigint,
trip_distance double,
RatecodeID bigint,
store_and_fwd_flag string,
PULocationID int,
DOLocationID int,
payment_type bigint,
fare_amount double,
extra double,
mta_tax double,
tip_amount double,
tolls_amount double,
improvement_surcharge double,
total_amount double,
congestion_surcharge double,
Airport_fee double,
month int,
year int)
PARTITIONED BY (`year`, `month`)
LOCATION '<glue_db_location>/yellow_taxi_trips'
TBLPROPERTIES (
'table_type'='iceberg',
'write_compression'='snappy'
);
Checking Prod Table Schema using Athena
This is where we can see the last point that I mentioned in understanding configuration aboutwarehousepath mentioned in SparkSession being overwritten by already present Glue Catalog Database, in this casenyc_tlc
Let's prepare data that will be written using WAP in yellow_taxi_trips table.
## Source data that will be written later in the table.
source_df = spark.read.parquet(f"{raw_data_path}/yellow/oct2023/")
source_df = source_df.withColumn("month", lit(10)) \
.withColumn("year", lit(2023))
source_df.groupBy("year", "month").count().show()Reading data that will serve as Source Table Data and will be written in yellow_taxi_trips
+----+-----+-------+
|year|month| count|
+----+-----+-------+
|2023| 10|3522285|
+----+-----+-------+Output
Alrighty everything is set to start with the WAP implementation now i.e.
- Production Table:
glue.nyc_tlc.yellow_taxi_trips - Source Data: data present in
source_df
WAP Implementation
Further steps show how to implement different stages in WAP i.e. Write - Audit - Publish with a bit of explanation.
Write
This stage ensures that we can safely write data into a branch created from the prod table so it's in isolation from the current production workloads.
- Create a Branch from the Table and set
write.wap.enabled=truein table properties for letting Iceberg table handle write using WAP Pattern
audit_branch = f"audit_102023"
# Create an Audit Branch for staging the new data before writing in prod table
spark.sql(f"ALTER TABLE {prod_table} CREATE BRANCH {audit_branch}")
# Verify if an audit branch is created.
spark.sql(f"select * from {prod_table}.refs").show(truncate=False)Creating a Branch from the Production Table
+------------+------+-------------------+-----------------------+---------------------+----------------------+
|name |type |snapshot_id |max_reference_age_in_ms|min_snapshots_to_keep|max_snapshot_age_in_ms|
+------------+------+-------------------+-----------------------+---------------------+----------------------+
|main |BRANCH|2498870574022386457|null |null |null |
|audit_102023|BRANCH|2498870574022386457|null |null |null |
+------------+------+-------------------+-----------------------+---------------------+----------------------+Output
# Set write.wap.enabled=true for table to write data into WAP Pattern.
spark.sql(f"ALTER TABLE {prod_table} SET TBLPROPERTIES ('write.wap.enabled'='true')")Setting 'write.wap.enabled' = 'true' for table to write data using the WAP pattern
Oncewrite.wap.enabledproperty is added in the table, Athena doesn't let you see the DDL Statement and throws an error sayingtable has unsupported propertybut you can still query the data.
Let's verify this property is added in table properties via Athena Console by running show create table nyc_tlc.yellow_taxi_trips

Whoops..!!! Unable to see the table DDL from Athena. Let's see if we can query the data in this table or that's broken too..!!
select "year", "month", count(*) from nyc_tlc.yellow_taxi_trips group by 1,2Verifying data in Production Table
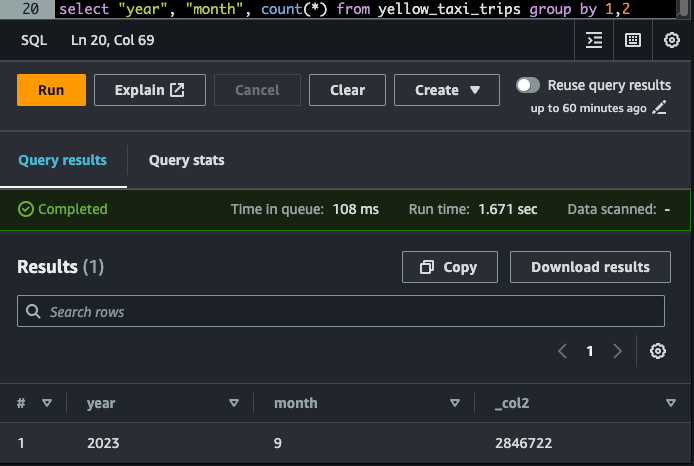
write.wap.enabled=true in table propertiesIt's important to UNSET the property from the production table to make the table DDL Queryable again.Let's verify table DDL via Spark directly
# Check table DDL
spark.sql(f"show create table {prod_table}").collect()[0]['createtab_stmt']"CREATE TABLE glue.nyc_tlc.yellow_taxi_trips (\n VendorID INT,\n tpep_pickup_datetime TIMESTAMP_NTZ,\n tpep_dropoff_datetime TIMESTAMP_NTZ,\n passenger_count BIGINT,\n trip_distance DOUBLE,\n RatecodeID BIGINT,\n store_and_fwd_flag STRING,\n PULocationID INT,\n DOLocationID INT,\n payment_type BIGINT,\n fare_amount DOUBLE,\n extra DOUBLE,\n mta_tax DOUBLE,\n tip_amount DOUBLE,\n tolls_amount DOUBLE,\n improvement_surcharge DOUBLE,\n total_amount DOUBLE,\n congestion_surcharge DOUBLE,\n Airport_fee DOUBLE,\n month INT,\n year INT)\nUSING iceberg\nPARTITIONED BY (year, month)\nLOCATION '<glue-db-location>/nyc_tlc/yellow_taxi_trips'\nTBLPROPERTIES (\n 'current-snapshot-id' = '2498870574022386457',\n 'format' = 'iceberg/parquet',\n 'format-version' = '2',\n 'write.parquet.compression-codec' = 'snappy',\n 'write.wap.enabled' = 'true')\n"write.wap.enabled is set in the table. The last property in the output
- Setting
spark.wap.branchin Spark Session
# setting WAP branch to Audit Branch in Spark Session so new data is written into Audit Branch
# this will make the default branch from main to audit_branch for this particular Spark Session i.e. all the queries being run without any refrence to other branch will run on audit_branch.
spark.conf.set("spark.wap.branch", audit_branch)Setting spark.wap.branch in SparkSession to audit_branch
- Writing Source Data into Production Table
# Appending data into Iceberg Prod Table
source_df.writeTo(prod_table).append()Writing Source data into Production Table
Let's verify the data in the prod table from Athena:
select "year", "month", count(*) from nyc_tlc.yellow_taxi_trips group by 1,2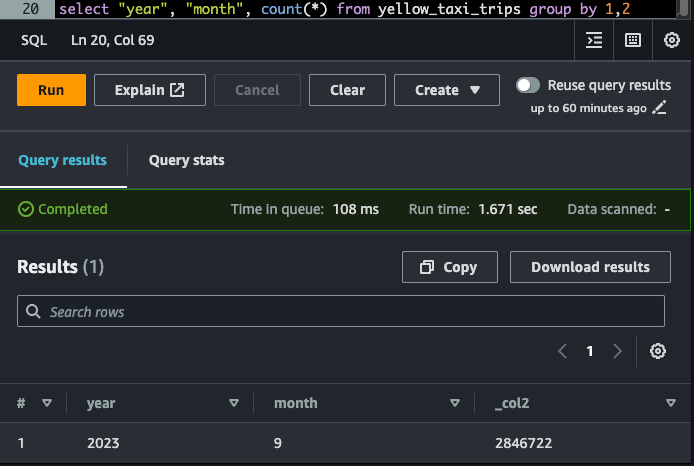
Looks like the Prod table data is intact. Let's check the same from spark.
# Let's verify data in prod table
spark.table(prod_table).groupBy("year", "month").count().show()Verifying the data from Spark
+----+-----+-------+
|year|month| count|
+----+-----+-------+
|2023| 10|3522285|
|2023| 9|2846722|
+----+-----+-------+Output
Yikes..!!!! the data in Spark seems different for the same query than in Athena. What the heck is happening? 🤯
The reason for this is:spark.wap.branchis set toaudit_branch. The actual branch that is being queried isaudit_branchand notmainbranch.
To query the main branch:
## Checking the data in main branch
spark.read.option("BRANCH", "main").table(prod_table).groupBy("year", "month").count().show()Reading data from main branch.
+----+-----+-------+
|year|month| count|
+----+-----+-------+
|2023| 9|2846722|
+----+-----+-------+Output
This verifies all the writes happening from the current SparkSession are in isolation from the Production Data in yellow_taxi_trips table.Audit
This stage enables us to understand the quality of our newly inserted data. During this stage, we can run various data quality checks such as inspecting NULL values, identifying duplicated data, etc.
You can define any of the DQ Processes here via some code, third-party provider, or any other service. A few of such options are:
- via Pydeequ
- via AWS Glue Data Quality
- via Pyspark/Pandas etc
I will be using the third option here via Pyspark for easy understanding.
Let's assume as per our application data quality standard, prod data shouldn't have any data with total_amount as negative.
Now based on whether your DQ Checks are successful or failed, you can discuss with stakeholders and decide what needs to be done in this case like:
- Do not publish the data as the DQ doesn't meet the expectation.
- DELETE the rows not meeting DQ standards and preserve such records somewhere else.
- Fix the data via some logic like populating null and missing value with some logic.
Running DQ Checks on audit_branch data
# Reading data from the Audit Branch:
audit_data = spark.read.option("BRANCH", audit_branch).table(prod_table)
# check if there are any rows with negative total_amount
neg_amt_df = audit_data.filter(col("total_amount") < 0)
Running predefined DQ checks to ensure data being written has good quality
Based on the DQ Result, decide what needs to be done. In case the data doesn't need to be published anymore, just drop the branch.
if not neg_amt_df.isEmpty():
# dropping Audit Branch
spark.sql(f"ALTER TABLE {prod_table} DROP BRANCH {audit_branch}")Dropping Branch in case of DQ Fails
If we can just discard the record and preserve them somewhere to be looked at later.
if not neg_amt_df.isEmpty():
# write rejected records in some table or someplace before deleting them.
neg_amt_df.write.partitionedBy("year","month").parquet("bad-data-location")
spark.sql(f"DELETE FROM {prod_table} where total_amount < 0")Deleting bad quality records and preserving them somewhere
Publish
This stage allows data to be made available to the production tables for consumption by the downstream analytical applications.
Once the Auditing is done and DQ is as expected or fixed. We can Publish these final records in the Production main branch by calling an Iceberg Store Procedure called glue.system.fast_forward.
# Fast forwarding Audit branch to main branch
spark.sql(f"""CALL glue.system.fast_forward('{prod_table}', 'main', '{audit_branch}')""").show()Publishing the data in audit_branch to Production
+--------------+-------------------+-------------------+
|branch_updated| previous_ref| updated_ref|
+--------------+-------------------+-------------------+
| main|2498870574022386457|8657093001848818796|
+--------------+-------------------+-------------------+Snapshot_id for the main branch before and after fast-forwarding
Let's verify if the data is present for querying in the table via Athena
select "year", "month", count(*) from nyc_tlc.yellow_taxi_trips group by 1,2Verifying data in Production Table via Athena
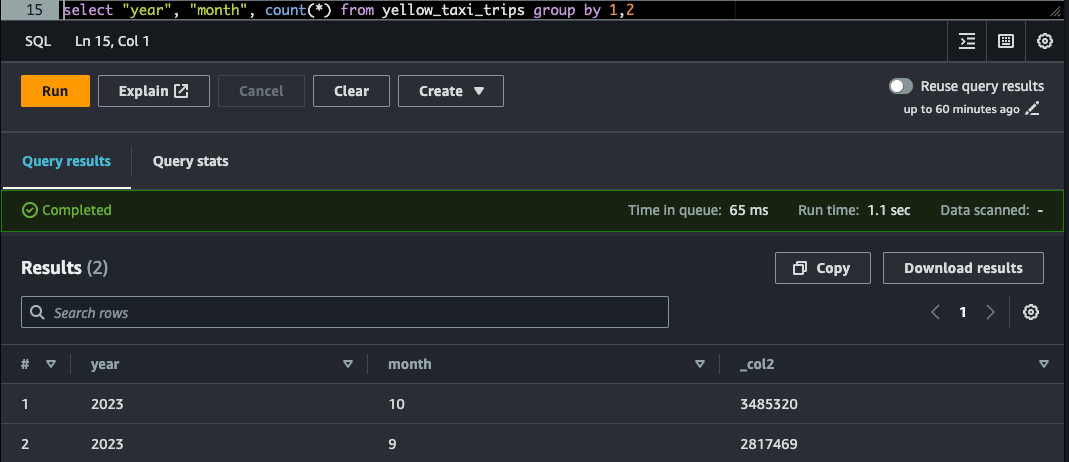
Unsetting Configuration/Property for WAP
Unsetting spark.wap.branch : Will let SparkSesion query the main branch, write.wap.enabled from the table will make Athena show DDL again for the table.
# Unset from SparkSession
spark.conf.unset('spark.wap.branch')
# unset from table properties so that create table ddl can be seen again on Athena.
spark.sql(f"ALTER TABLE {prod_table} UNSET TBLPROPERTIES ('write.wap.enabled')")Unsetting spark.wap.branch and write.wap.enabled
Now, we can also drop the audit_branch as data is published and if you will look into the refs metadata table for the yellow_taxi_trips table, it will be pointing to the same snapshot_ids.
# Once the fast forward is done, both the branch will be pointing to the same snapshot so audit branch can be dropped if required.
spark.sql(f"ALTER TABLE {prod_table} DROP BRANCH {audit_branch}")Dropping audit_branch
That's it for this one folks..!!!
If you have read until here, please leave a comment below, and any feedback is highly appreciated. See you in the next post..!!! 😊
If it has added any value to you, consider subscribing, it's free of cost and you will get the upcoming posts into your mailbox too.





Member discussion